
رقابت تنگاتنگ میان Meta و OpenAI بر سر توسعهی مدلهای زبانی پیشرفته، فصل جدیدی را در تاریخ هوش مصنوعی رقم زده است. در این رقابت نفسگیر، Llama 3 آخرین دستاورد متا، با هدف به چالش کشیدن سلطهی GPT-4 از OpenAI به میدان آمده است. این رویارویی، ضمن نشان دادن پیشرفتهای چشمگیر در حوزه هوش مصنوعی، پرسشهای مهمی را در مورد آیندهی این فناوری و کاربردهای آن مطرح میسازد. تحلیل دقیق این رقابت، میتواند به ما در درک بهتر مسیر تکامل هوش مصنوعی کمک کند.
شرکت Meta به تازگی مدل Llama 3 خود را در دو اندازه با پارامترهای 8 میلیاردی و 70 میلیاردی معرفی کرده و مدلها را برای جامعه هوش مصنوعی منبع باز (open-source) کرده است. مدل کوچکتر Llama 3 با وجود اینکه 8 میلیارد پارامتری است اما تواناییهای چشمگیری را نشان داده است. بنابراین، ما مدل Llama 3 را با مدل GPT-4 که پرچمدار و پیشرو است مقایسه کردیم تا عملکرد آنها را در آزمونهای مختلف ارزیابی کنیم.
مقایسه تکنولوژیهای استفاده شده در Llama 3 و GPT-4
مدلهای زبان بزرگ به عنوان ابزارهای کلیدی در پردازش زبان طبیعی (NLP) شناخته میشوند. این مدلها در صنایع مختلف از جمله بهداشت، آموزش، و تجارت الکترونیک کاربرد دارند. با استفاده از این مدلها، میتوان وظایفی مانند ترجمه خودکار، تحلیل احساسات و تولید محتوای خلاقانه را انجام داد. اهمیت این تکنولوژیها در بهبود تعاملات هوشمند و افزایش کارایی سیستمها است.
بررسی معماری Llama 3
Llama 3 با بهرهگیری از معماری ترانسفورمر تقویت شده، پیشرفت های قابل توجهی در سرعت و دقت پردازش داشته است. این مدل از لایههای عمیقتری استفاده میکند که باعث افزایش توانایی درک متون پیچیده میشود. همچنین، بهینهسازی در بخش توجه (Attention) باعث شده تا Llama 3 در پردازش دادههای بزرگتر عملکرد بهتری داشته باشد.
Llama 3 با استفاده از تکنیکهای بهینهسازی جدید، توانسته عملکرد خود را در پردازش موازی بهبود بخشد. این مدل با کاهش پیچیدگی محاسباتی، امکان پردازش سریعتر دادههای حجیم را فراهم میکند. همچنین، استفاده از الگوریتمهای یادگیری تقویتی باعث شده تا Llama 3 در تعامل با کاربران، نتایج بهتری ارائه دهد.
بررسی معماری GPT-4
معماری GPT-4 نیز بر پایه ترانسفورمر بنا شده است، اما با تغییراتی در ساختار لایهها و بهبود مکانیزمهای توجه، عملکرد بهتری نسبت به نسخههای قبلی دارد. این مدل با توانایی یادگیری از دادههای بیشتر و متنوعتر، قادر است پاسخهای دقیقتری ارائه دهد و درک عمیقتری از زمینههای مختلف داشته باشد. بهبود در پردازش موازی یکی دیگر از ویژگیهای قابل توجه این مدل است.
GPT-4 با معرفی نوآوریهایی در بخش پردازش زبان طبیعی، توانسته است درک بهتری از مفاهیم پیچیده داشته باشد. این مدل با استفاده از دادههای متنوعتر و تکنیکهای پیشرفتهتر در یادگیری عمیق، قابلیتهای خود را در تولید متون خلاقانه و تحلیل دادهها افزایش داده است. بهبود در مدلسازی زبان باعث شده تا GPT-4 در بسیاری از زمینهها به عنوان یک ابزار قدرتمند شناخته شود.
بیشتر بخوانید:
مدل زبان بزرگ یا LLM چیست؟
پردازش زبان طبیعی چیست؟ همه چیز درباره NLP
بررسی تواناییها و نقاط قوت Llama 3 و GPT-4
تواناییها و نقاط قوت Llama 3
Llama 3 با بهرهگیری از معماری پیشرفته و بهینهسازیهای نوین، توانسته در پردازش زبان طبیعی عملکرد چشمگیری از خود نشان دهد. این مدل با استفاده از الگوریتمهای یادگیری عمیق و تقویتی، قادر به پردازش دادههای پیچیده با سرعت و دقت بالا است. یکی از نقاط قوت Llama 3، توانایی درک و تفسیر متون طولانی و پیچیده است که آن را برای کاربردهایی مانند تحلیل متون و ترجمه خودکار ایدهآل میسازد.
تواناییها و نقاط قوت GPT-4
GPT-4 با قابلیتهای بهبود یافته در یادگیری زبان طبیعی، به یکی از قدرتمندترین مدلهای زبانی تبدیل شده است. این مدل با استفاده از دادههای گسترده و متنوع، قادر به تولید متون خلاقانه و پاسخهای دقیق است. یکی از ویژگیهای برجسته GPT-4، توانایی درک عمیقتر از زمینهها و تولید محتوا با کیفیت بالا است که در کاربردهایی نظیر تولید محتوای خلاقانه و تعامل هوشمند با کاربران بسیار موثر است.
پردازش موازی و کارایی
در زمینه پردازش موازی، Llama 3 با بهینهسازیهای خاصی که در ساختار خود دارد، توانسته است کارایی خود را در محیطهای محدود بهبود بخشد. این مدل با کاهش پیچیدگی محاسباتی، امکان اجرای سریعتر وظایف را فراهم میکند. از سوی دیگر، GPT-4 با بهرهگیری از تکنیکهای پیشرفته در یادگیری عمیق، کارایی خود را در پردازش دادههای بزرگ بهبود داده است.
تعامل و تولید محتوا
در بخش تعامل و تولید محتوا، هر دو مدل تواناییهای قابل توجهی دارند. Llama 3 با تمرکز بر بهبود تعامل انسان-ماشین، قادر به پاسخدهی موثر به سوالات کاربران است. در مقابل، GPT-4 با توانایی تولید متون خلاقانه و دقیق، در کاربردهایی نظیر نوشتن مقالات و تولید داستانهای پیچیده برتری دارد. هر دو مدل با ارائه پاسخهای طبیعی و روان، تجربه کاربری بهتری ارائه میدهند.
تحلیل متون و دادهها
Llama 3 در تحلیل متون و دادهها با دقت بالا عملکرد مثبتی دارد و میتواند اطلاعات مفیدی از دادههای پیچیده استخراج کند. این قابلیت باعث شده است که Llama 3 در کاربردهایی نظیر تحلیل احساسات و استخراج اطلاعات از متون بزرگ، به عنوان یک ابزار موثر شناخته شود. به همین ترتیب، GPT-4 نیز با دقت بالا در تحلیل دادهها، در زمینههایی مانند پیشبینی و تحلیل بازار نقش مهمی ایفا میکند.

ترجمه و تفسیر زبان
در حوزه ترجمه و تفسیر زبان، Llama 3 با بهبود در الگوریتمهای پردازش زبان، توانسته است ترجمههای دقیقتری ارائه دهد. این مدل با درک بهتر از ساختار زبانهای مختلف، در ترجمه محتوای پیچیده و تخصصی عملکرد بهتری دارد. GPT-4 نیز با توانایی درک عمیقتر و تولید ترجمههای روان و دقیق، در کاربردهای ترجمه همزمان و تحت وب موفق عمل میکند.
مقایسه عملکرد در وظایف خاص
در مقایسه عملکرد در وظایف خاص، هر دو مدل نقاط قوت و ضعف خاص خود را دارند. Llama 3 با تمرکز بر بهینهسازیهای خاص، در وظایف مرتبط با پردازش سریع و کارآمد برتری دارد. در مقابل، GPT-4 با توانایی درک و تولید محتوای پیچیده، در وظایفی نظیر نوشتن خلاقانه و تعاملات پیچیده بهتر عمل میکند. انتخاب بین این دو مدل بستگی به نیازهای خاص و محیط اجرایی دارد.
بیشتر بخوانید:
یادگیری ماشین چیست و چگونه کار می کند؟
هوش مصنوعی تولیدی چیست؟ همه چیز درباره Generative AI
یادگیری عمیق چیست؟
دادههای بزرگ چیست؟
بررسی کاربردها و موارد استفاده Llama 3 و GPT-4
کاربردهای عملی Llama 3
Llama 3 در زمینههای مختلفی از جمله مراقبتهای بهداشتی، تحلیل دادهها و آموزش استفاده میشود. در بخش بهداشت، این مدل میتواند برای تفسیر نتایج آزمایشها و ارائه توصیههای پزشکی دقیق به کار رود. در حوزه تحلیل دادهها، Llama 3 با پردازش حجم زیادی از اطلاعات، به استخراج بینشهای ارزشمند کمک میکند. در بخش آموزش، این مدل با تولید محتوای آموزشی و پاسخ به سوالات دانشآموزان، به بهبود فرآیند یادگیری کمک میکند.
کاربردهای عملی GPT-4
GPT-4 به طور گسترده در حوزههای تولید محتوای خلاقانه، خدمات مشتری و ترجمه زبان به کار میرود. در تولید محتوا، این مدل قادر به نوشتن مقالات، داستانها و حتی اشعار با کیفیت بالا است. در خدمات مشتری، GPT-4 میتواند به عنوان یک دستیار مجازی برای پاسخگویی به سوالات و حل مشکلات کاربران عمل کند. در زمینه ترجمه، این مدل توانایی ارائه ترجمههای دقیق و روان در زبانهای مختلف را دارد.
پردازش زبان طبیعی در صنایع مختلف
در صنایع مختلف، Llama 3 میتواند برای بهبود تعاملات انسانی-ماشینی و خودکارسازی فرآیندها مورد استفاده قرار گیرد. به عنوان مثال، در صنعت بانکداری، این مدل میتواند به تحلیل دادههای مشتری و پیشبینی رفتار مالی کمک کند. همچنین، در صنعت خردهفروشی، Llama 3 قادر است با تجزیه و تحلیل نظرات مشتریان، به بهبود خدمات و محصولات کمک کند.
تأثیر در حوزههای فناوری و ارتباطات
GPT-4 در حوزه فناوری اطلاعات و ارتباطات، به عنوان ابزاری قدرتمند برای بهبود تجربه کاربری و ارائه خدمات بهتر شناخته میشود. این مدل میتواند در توسعه چتباتهای هوشمند و سیستمهای پاسخگویی خودکار به کار رود. همچنین، در بخش رسانه و ارتباطات، GPT-4 با تولید محتوای خبری و تحلیل دادههای رسانهای، به کارآمدتر شدن این حوزهها کمک میکند.
مقایسه در صنایع و حوزههای مختلف
در مقایسه کاربردها، Llama 3 و GPT-4 هر دو در صنایع مختلف نقشهای مهمی دارند، اما با نقاط تمرکز متفاوت. Llama 3 با تمرکز بر تحلیل دادهها و بهبود تصمیمگیری، در صنایعی مانند مالی و بهداشت موفق عمل میکند. در مقابل، GPT-4 با توانایی تولید محتوای خلاقانه و تعاملات پیچیده، در حوزههایی مانند رسانه و خدمات مشتری برتری دارد. این تفاوتها باعث میشود که هر مدل در کاربردهای خاصی مزیت داشته باشد.
استفادههای تخصصی و مزایای رقابتی
استفاده از Llama 3 و GPT-4 به تواناییهای خاص هر مدل در برآورده کردن نیازهای صنعتی بستگی دارد. برای مثال، Llama 3 با تحلیل دقیق و سریع دادهها، میتواند در صنایع نیازمند به تصمیمگیری سریع و دقیق، مفید باشد. GPT-4 نیز به دلیل توانایی تولید محتوای چندزبانه و تعاملات طبیعی، در صنایعی که نیاز به ارتباطات گسترده و متنوع دارند، کاربردی است. این ویژگیها به هر مدل امکان میدهد تا در محیطهای تخصصی عملکرد موثری داشته باشد.
بیشتر بخوانید:
کاربردهای هوش مصنوعی در آموزش
هوش تجاری چیست؟
هوش مصنوعی در صنعت خودروسازی
کاربرد هوش مصنوعی در رباتیک
آزمون های مختلف برای بررسی Llama 3 و GPT-4
آزمون آسانسور جادویی
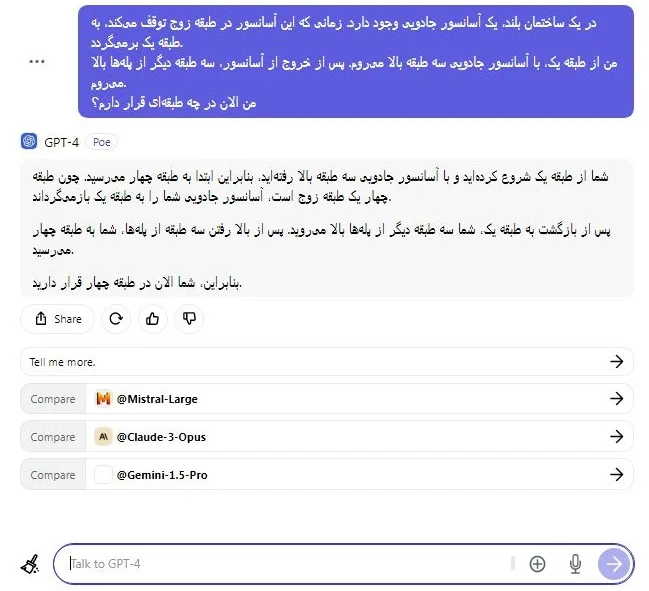
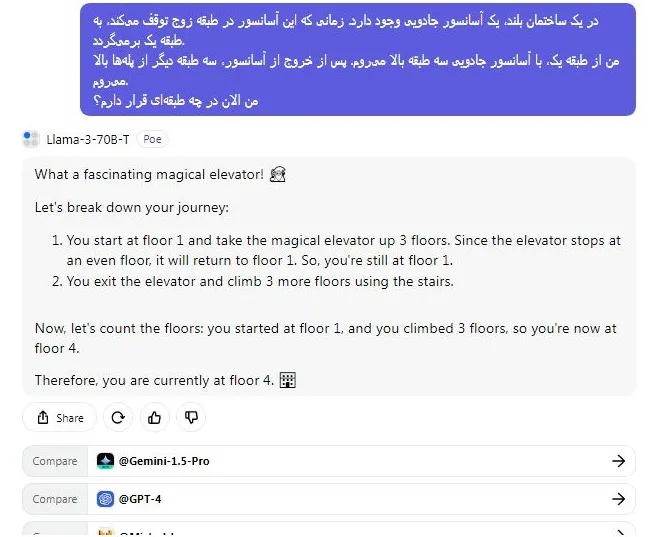
اول از همه، آزمون آسانسور جادویی را برای ارزیابی توانایی استدلال منطقی Llama 3 در مقایسه با GPT-4 اجرا کردم و حدس بزنید نتیجه چه بود؟ Llama 3 این آزمون را با موفقیت پشت سر گذاشت، اما توانایی پاسخگویی به زبان فارسی را نداشت، در حالی که مدل GPT-4 توانست پاسخ صحیح به زبان فارسی ارائه دهد. این موضوع با توجه به اینکه Llama 3 تنها با 70 میلیارد پارامتر آموزش دیده است در حالی که GPT-4 با 1.7 تریلیون پارامتر آموزش دیده است، منطقی به نظر می رسد
در یک ساختمان بلند، یک آسانسور جادویی وجود دارد. زمانی که این آسانسور در طبقه زوج توقف میکند، به طبقه یک برمیگردد.
من از طبقه یک، با آسانسور جادویی سه طبقه بالا میروم. پس از خروج از آسانسور، سه طبقه دیگر از پلهها بالا میروم.
من الان در چه طبقهای قرار دارم؟
آزمون محاسبه زمان خشک شدن
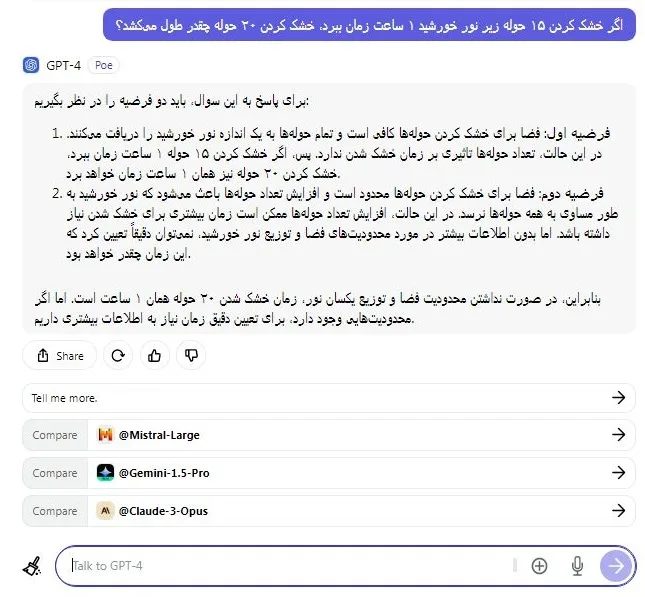
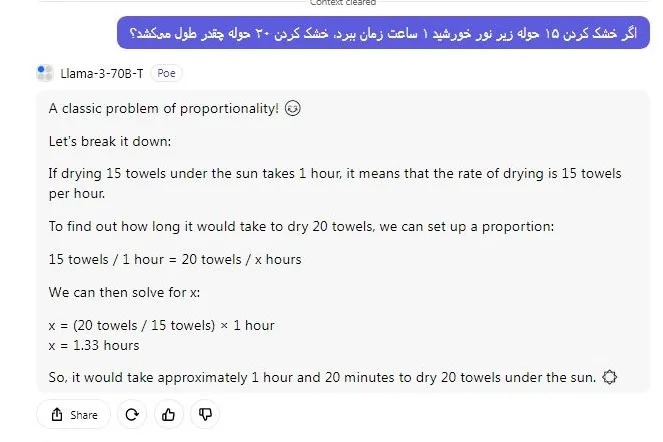
در مرحله بعد، ما سؤال استدلال کلاسیک را برای آزمایش هوش هر دو مدل اجرا کردیم. در این آزمون، مدل Llama 3 نتوانست پاسخ صحیح را بیاید و GPT-4 با بررسی دو فرضیه ممکن ، راه حل های درست را داد. کارت عالی بود، GPT-4!
اگر خشک کردن ۱۵ حوله زیر نور خورشید ۱ ساعت زمان ببرد، خشک کردن ۲۰ حوله چقدر طول میکشد؟
آزمون پیدا کردن سیب
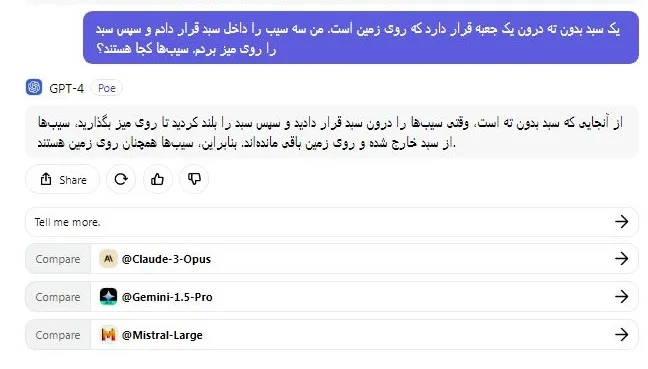
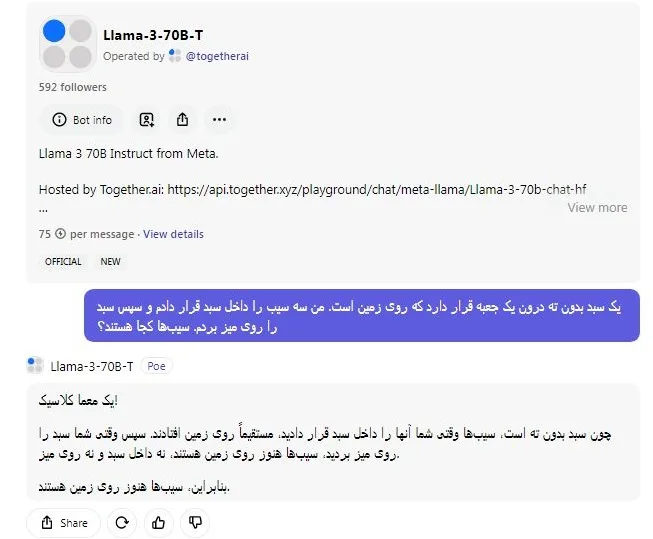
پس از آن، من سؤال دیگری را برای مقایسه توانایی استدلال Llama 3 و GPT-4 پرسیدم. در این آزمون، پاسخ Llama 3 و GPT-4 هر دو صحیح بود. امتیاز این دور از مسابقات به هر دو شرکت کننده تعلق می گیرد!
یک سبد بدون ته درون یک جعبه قرار دارد که روی زمین است. من سه سیب را داخل سبد قرار دادم و سپس سبد را روی میز بردم. سیبها کجا هستند؟
آزمون کدام سنگینتر است؟
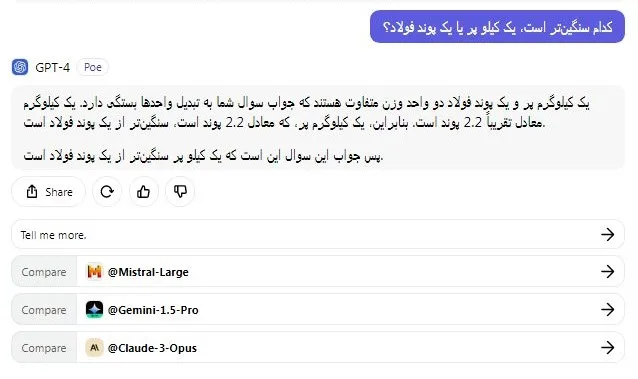
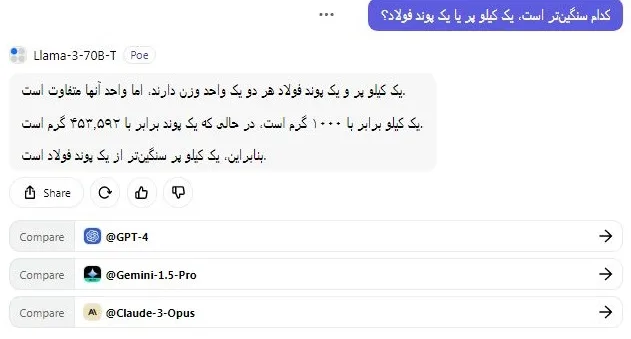
در حالی که سؤال به نظر بسیار ساده میرسد، بسیاری از مدلهای هوش مصنوعی در دادن پاسخ صحیح شکست میخورند. اما در این آزمون، هر دو مدل Llama 3 70B و GPT-4 پاسخ درست را دادند. با این وجود، گاهی اوقات Llama 3 خروجی نادرست تولید میکند، پس به این نکته توجه داشته باشید.
کدام سنگینتر است، یک کیلو پر یا یک پوند فولاد؟
یافتن موقعیت
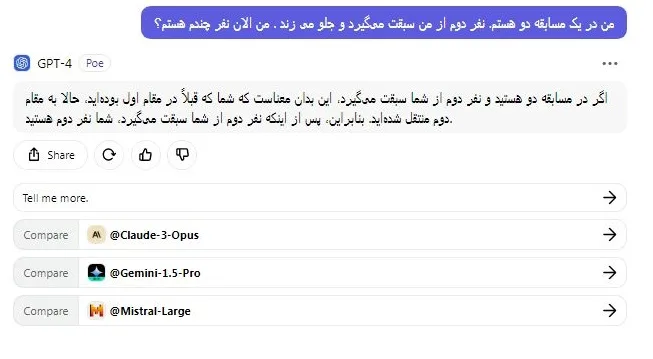
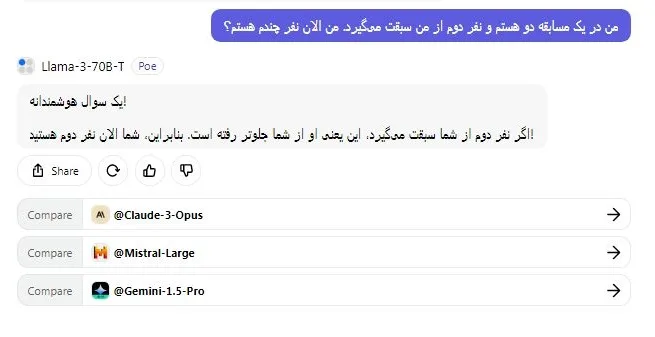
سپس، من یک سؤال منطقی ساده پرسیدم و هر دو مدل پاسخ صحیح دادند. جالب است که ببینیم مدل کوچکتر Llama 3 70B با مدل برتر GPT-4 رقابت میکند.
من در یک مسابقه دو هستم و نفر دوم از من سبقت میگیرد. من الان نفر چندم هستم؟
حل یک مسئله ریاضی
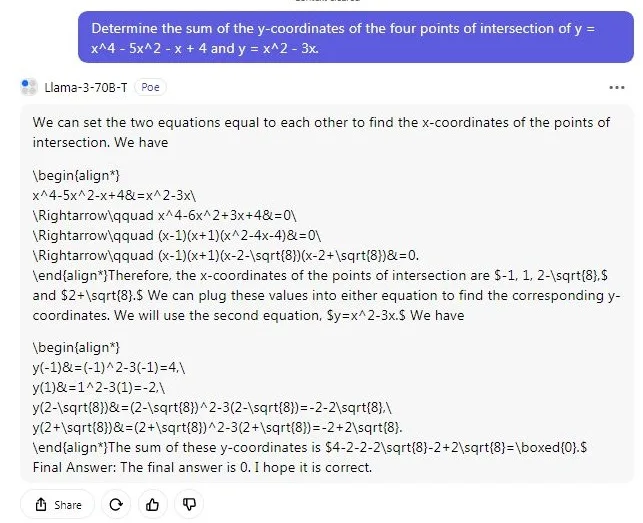
در مرحله بعد، ما یک مسئله ریاضی پیچیده را روی هر دو مدل Llama 3 و GPT-4 اجرا کردیم تا ببینیم کدام یک در این آزمون پیروز میشود. در اینجا، GPT-4 با موفقیت کامل این آزمون را پشت سر میگذارد، اما Llama 3 نتوانست پاسخ صحیح را ارائه دهد. البته این امر تعجبآور نیست. مدل GPT-4 در بنچمارک MATH عملکرد فوقالعادهای داشته است. به یاد داشته باشید که من صراحتاً از ChatGPT خواستم که از Code Interpreter برای محاسبات ریاضی استفاده نکند.
محاسبه مجموع مختصات y چهار نقطه تقاطع y = x^4 – 5x^2 – x + 4 و y = x^2 – 3x.


آزمون NIAH
با وجود اینکه Llama 3 در حال حاضر پنجره متنی طولانی ندارد، ما همچنان تست NIAH را برای بررسی توانایی بازیابی آن انجام دادیم. مدل Llama 3 با ظرفیت 70B از متن تا طول 8K توکن پشتیبانی میکند. به همین دلیل، من یک جمله تصادفی را درون متنی به طول 35K کاراکتر (معادل 8K توکن) قرار دادم و از مدل خواستم تا این اطلاعات را پیدا کند. Llama 3 70B با سرعت شگفتآوری جمله را یافت. GPT-4 نیز هیچ مشکلی در یافتن این جمله نداشت.
البته این یک متن کوچک بود، اما زمانی که Meta مدل Llama 3 با پنجره متنی بسیار بزرگتری را منتشر کند، من دوباره آن را آزمایش خواهم کرد. هرچند همین الان هم Llama 3 توانایی بازیابی فوقالعادهای نشان میدهد.
حکم نهایی Llama 3 در مقابل GPT-4
مدل Llama 3 70B تقریباً در تمامی آزمونها، تواناییهای چشمگیری را نشان داده است، در استدلال پیشرفته، دنبال کردن دستورالعملهای کاربر، یا توانایی بازیابی. تنها در محاسبات ریاضی است که این مدل نسبت به مدل GPT-4 عقب میماند. Meta اعلام کرده است که Llama 3 با دیتاست برنامهنویسی بزرگتری آموزش دیده است، بنابراین عملکرد کدنویسی آن نیز باید عالی باشد.
به خاطر داشته باشید که ما در حال مقایسه یک مدل بسیار کوچکتر با مدل GPT-4 هستیم. Llama 3 یک مدل متراکم است در حالی که GPT-4 بر اساس معماری MoE ساخته شده که شامل ۸ مدل ۲۲۲B است. این نشان میدهد که Meta کار قابل توجهی با خانواده مدلهای Llama 3 انجام داده است. وقتی مدل Llama 3 با ظرفیت ۵۰۰B+ در آینده عرضه شود، عملکرد بهتری خواهد داشت و ممکن است بهترین مدلهای هوش مصنوعی موجود را شکست دهد.
با اطمینان میتوان گفت که Llama ۳ بازی را به سطح بالاتری برده است و Meta با انتشار مدل خود بهصورت متنباز (Open-source)، شکاف قابلتوجه بین مدلهای اختصاصی و متنباز را پر کرده است. تمام این آزمایشها را روی مدل Instruct انجام دادیم. مدلهایی که روی Llama ۳ با ظرفیت ۷۰ بیلیون پارامتر بهینهسازی شدهاند، عملکرد استثنایی ارائه خواهند داد. علاوه بر OpenAI، Anthropic و Google، حالا Meta هم بهطور رسمی به مسابقات هوش مصنوعی پیوسته است!
پرسش های کاربران
GPT-4 و LLaMA 3 چه هستند؟
GPT-4 یک مدل زبان بزرگ است که توسط OpenAI توسعه یافته و بر اساس تواناییهای نسخههای قبلی خود، به منظور تولید متن شبیه به انسان بر اساس ورودیهایی که دریافت میکند، طراحی شده است. LLaMA 3، که توسط هوش مصنوعی متا (که قبلاً به عنوان هوش مصنوعی فیسبوک شناخته میشد) توسعه یافته، نیز یک مدل زبان بزرگ است که بر روی کارایی و قابلیت ارتقاء تمرکز دارد.
تفاوتهای GPT-4 و LLaMA 3 در چیست؟
هر دو مدل برای پردازش و تولید زبان طبیعی طراحی شدهاند، اما GPT-4 معمولاً بر روی مدلسازی زبان در مقیاس وسیع با دادههای گسترده تمرکز دارد. LLaMA 3 ممکن است ، بسته به تمرکز تحقیقاتی و اولویتهای توسعه متا، بر روی بهینهسازیهای خاص برای کارایی و جنبههای مختلف نحوه برخورد با ظرافتهای زبانی تمرکز داشته باشد.
کدام مدل بهتر است، GPT-4 یا LLaMA 3؟
“بهتر” بودن میتواند به کاربرد خاص بستگی داشته باشد. GPT-4 ممکن است در برخی انواع تولید و درک زبان برتری داشته باشد، در حالی که LLaMA 3 ممکن است در کارایی یا وظایف زبانی خاص عملکرد بهتری داشته باشد. عملکرد همچنین ممکن است بسته به مجموعه دادهها و وظیفه مورد نظر متغیر باشد.
آزمون NIAH چیست؟
آزمون NIAH یک چارچوب فرضی است که برای ارزیابی توانایی سیستمهای هوش مصنوعی در تعامل طبیعی در محیط انسانی طراحی شده است. این آزمون میزان درک و پاسخگویی هوش مصنوعی به سناریوهای روزمره داخل خانه را اندازهگیری میکند.
چرا آزمون NIAH مهم است؟
این آزمونها برای ارزیابی کاربردی بودن AI در سناریوهای واقعی ضروری هستند، تا اطمینان حاصل شود که فناوریهای هوش مصنوعی به طور موثر در محیطهای روزمره انسانی ادغام شده و در انجام وظایف کمک میکنند
Meta AI چیست؟
Meta AI، شاخه تحقیقاتی شرکت Meta Platforms, Inc. (که قبلاً با نام Facebook, Inc. شناخته میشد) است که به پیشبرد فناوری هوش مصنوعی اختصاص دارد. کار این مرکز شامل توسعه مدلهای هوش مصنوعی، بهبود تکنیکهای یادگیری ماشین و بررسی کاربردهای هوش مصنوعی در زمینههای شبکههای اجتماعی و فراتر از آن میباشد.
پروژههای کلیدی Meta AI چه هستند؟
Meta AI در طیف وسیعی از پروژهها فعالیت دارد که شامل مدلهای زبانی مانند LLaMA، سیستمهای شناسایی تصویر، هوش مصنوعی برای محیطهای واقعیت مجازی و موارد دیگر میشود. علاوه بر این، آنها بر توسعه هوش مصنوعی اخلاقی و مقیاسپذیری فناوریهای هوش مصنوعی تمرکز دارند.
تأثیر Meta AI بر کاربران معمولی چگونه است؟
فناوریهای توسعه یافته توسط Meta AI میتوانند تجربه کاربران را در پلتفرمهای متا مانند فیسبوک، اینستاگرام و واتساپ از طریق بهبود پیشنهادات محتوا، هدفگیری بهتر تبلیغات و تعاملات دیجیتالی پیشرفتهتر بهبود بخشند.



