
مدلهای زبان بینایی، ترکیبی از تکنیکهای پردازش زبان طبیعی و بینایی کامپیوتری هستند که با استفاده از شبکههای عصبی پیچشی و ترنسفورمرها، توانایی درک و تولید اطلاعات تصویری و متنی به صورت همزمان را دارند. این مدلها، تصاویر و متنها را به فضای برداری نگاشت میکنند و با بهرهگیری از مکانیزم توجه، ارتباطات معنایی بین تصاویر و متنها را یاد میگیرند تا توانایی انجام کارهایی مانند توصیف تصاویر، جستجوی چندوجهی و درک صحنهها و اشیاء را به دست آورند.
PaliGemma خانواده جدیدی از مدلهای زبان بینایی گوگل است که میتواند تصویر و متنی را دریافت کرده و متنی را خروجی دهد. تیم گوگل سه نوع مدل منتشر کرده است: مدلهای پیشآموزش دیده (pt)، مدلهای میکس و مدلهای تنظیم شده (ft)، هرکدام با وضوح و دقت مختلف، برای اهداف گوناگون در دسترس هستند.
تمام مدلها در مخزنهای مدل هاب هاگینگ فیس (Hugging Face Hub model) با کارتهای مدل و لایسنسهای آنها منتشر شده و دارای ادغام ترانسفورمرها هستند.
بیشتر بخوانید: مدل زبان بینایی
PaliGemma چیست؟
PaliGemma یک مدل زبان-بینایی باز (VLM) است که از PaLI-3 الهام گرفته شده و با اجزای باز ساخته شده است، مانند مدل بینایی SigLIP و مدل زبان Gemma.
PaliGemma (گیتهاب) به عنوان یک مدل چندمنظوره برای انتقال به مجموعهای گسترده از وظایف زبان-بینایی مانند توضیح تصویر و ویدیوهای کوتاه، پاسخ به سوالات بصری، خواندن متن، تشخیص اشیا و تقسیمبندی اشیا طراحی شده است.
PaliGemma مانند CLIP، از رمزگذار تصویر و متنی است که به طور مشترک آموزش داده شدهاند. مشابه PaLI-3، مدل ترکیبی PaliGemma بر روی دادههای تصویر-متن، آموزش دیده و به راحتی میتواند بر روی وظایف مورد نظر کاربران مانند توضیح دادن تصاویر یا تقسیمبندی ارجاعی تنظیم شود. Gemma یک مدل فقط برای تولید متن است. ترکیب رمزگذار تصویر SigLIP با Gemma با استفاده از یک آداپتور خطی PaliGemma را به یک مدل قدرتمند زبان بینایی تبدیل میکند.
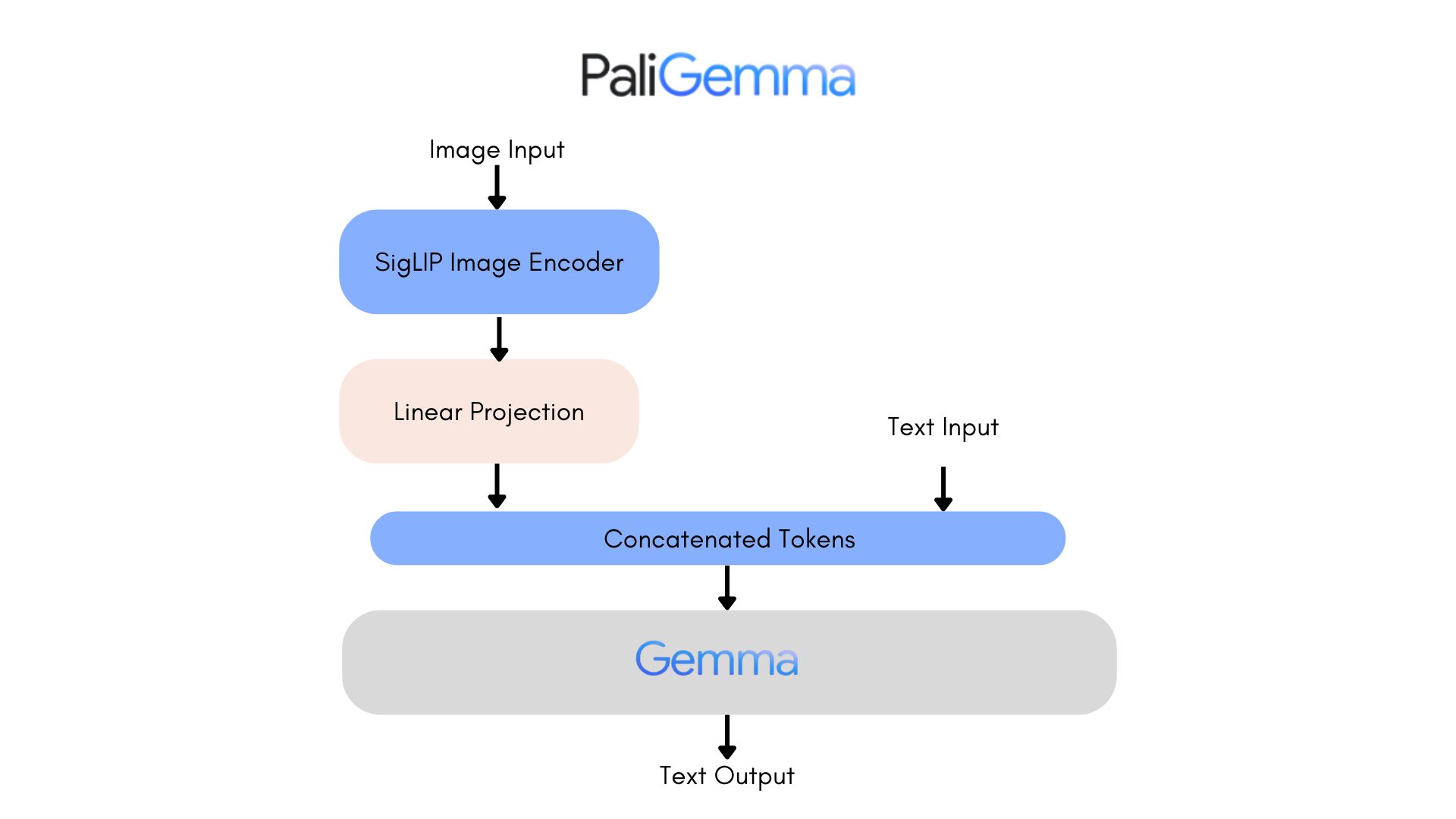
PaliGemma در سه مدل منتشر شده است:
- چکپوینت PT: مدلهای پیشآموزش دیدهای که میتوانند برای وظایف پاییندستی تنظیم شوند.
- چکپوینت ترکیبی: مدلهای PT که برای ترکیبی از وظایف تنظیم شدهاند. آنها برای استنباط عمومی با دستورات متن آزاد مناسب هستند و فقط برای اهداف تحقیقاتی قابل استفاده هستند.
- چکپوینت FT: مجموعهای از مدلهای تنظیم شدهاند، که هر کدام تخصصی برای یک شاخص آکادمیک دارند. آنها در وضوحهای مختلف موجود هستند و فقط برای اهداف تحقیقاتی در نظر گرفته شدهاند.
مدلها در سه وضوح مختلف (۲۲۴x۲۲۴، ۴۴۸x۴۴۸، ۸۹۶x۸۹۶) و سه دقت مختلف (bfloat16، float16، و float32) عرضه میشوند. هر مخزن شامل چکپوینت هایی برای یک وضوح و وظیفه مشخص است، با سه بازنگری برای هر یک از دقتهای موجود. شاخه اصلی هر مخزن شامل چکپوینت float32 است، در حالی که بازنگریهای bfloat16 و float16 شامل دقتهای مربوطه هستند. مخازن جداگانهای برای مدلهای سازگار با ترانسفورمرها و با پیادهسازی اصلی JAX وجود دارد.
همانطور که در ادامه به تفصیل توضیح داده شده است، مدلهای با وضوح بالا به دلیل طولانیتر بودن دنبالههای ورودی، به حافظه بسیار بیشتری برای اجرا نیاز دارند. آنها ممکن است برای وظایف دقیق مانند OCR مفید باشند، اما نسخههای ۲۲۴ برای بیشتر اهداف کاملاً مناسب هستند.
بیشتر بخوانید: پردازش زبان طبیعی چیست؟ همه چیز درباره NLP
بیشتر بخوانید: بهترین مدل زبان بزرگ یا LLM کدام است؟
قابلیتهای مدل
PaliGemma یک مدل زبان بینایی تکنوبتی است که برای استفاده محاورهای طراحی نشده و بهترین کارایی را هنگام تنظیم برای یک مورد استفاده خاص دارد.
شما میتوانید با شرطی کردن مدل با پیشوندهای وظیفه، مانند تشخیص (detect) یا قطعهبندی (segment)، تنظیم کنید که چه وظیفهای را انجام دهد. مدلهای آموزش دیده، به این شیوه آموزش دیدهاند تا مجموعهای غنی از قابلیتها (پاسخ به سوالات، توضیح تصاویر، قطعهبندی و غیره) به آنها تزریق شود. با این حال، طراحی آنها به گونهای نیست که مستقیماً استفاده شوند، بلکه برای انتقال (با تنظیم دقیق) به وظایف خاص با استفاده از ساختار دستور مشابه طراحی شدهاند. برای آزمایش تعاملی، میتوانید از خانواده مدلهای “میکس” استفاده کنید که بر روی مخلوطی از وظایف، تنظیم دقیق شدهاند.
نمونههای زیر از چکپوینت میکس برای نمایش برخی از قابلیتها استفاده میکنند.
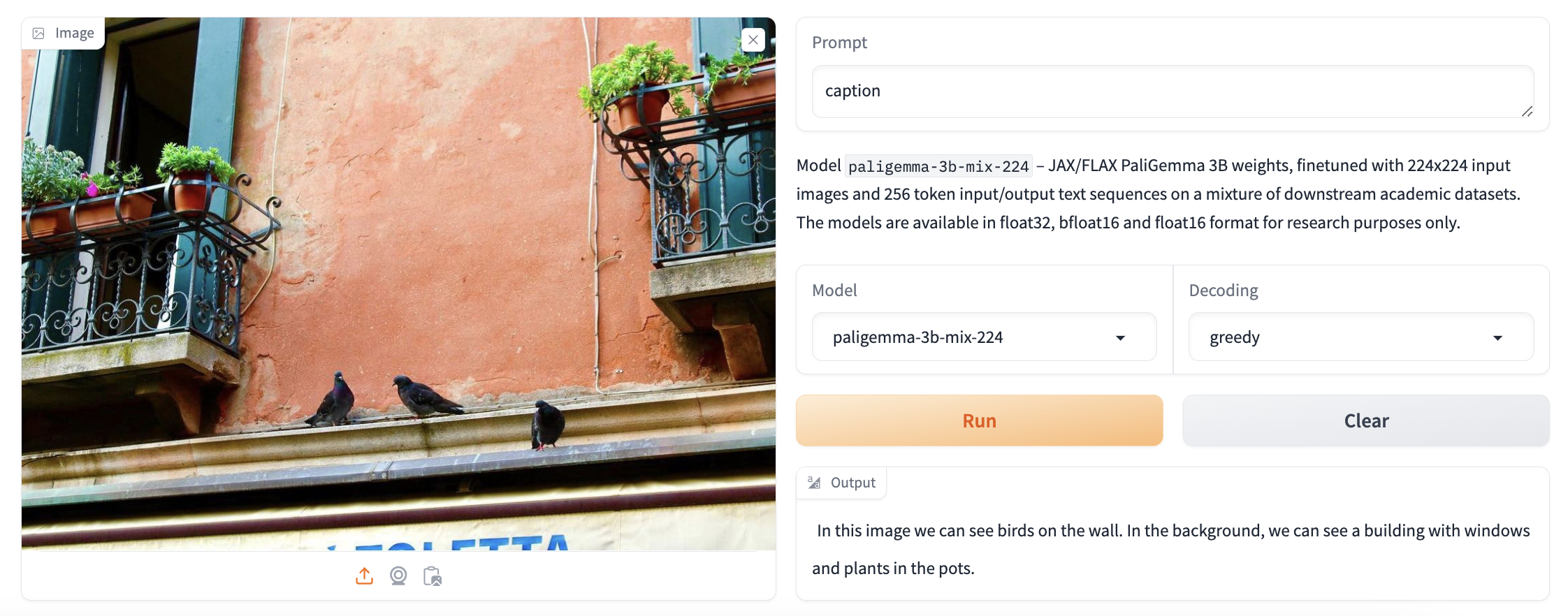
توضیح تصویر
PaliGemma میتواند عناصر موجود در تصاویر را شرح و توضیح دهد. شما میتوانید با چکپوینت میکس از دستورات توضیح مختلف استفاده کنید تا ببینید چگونه پاسخ میدهند.
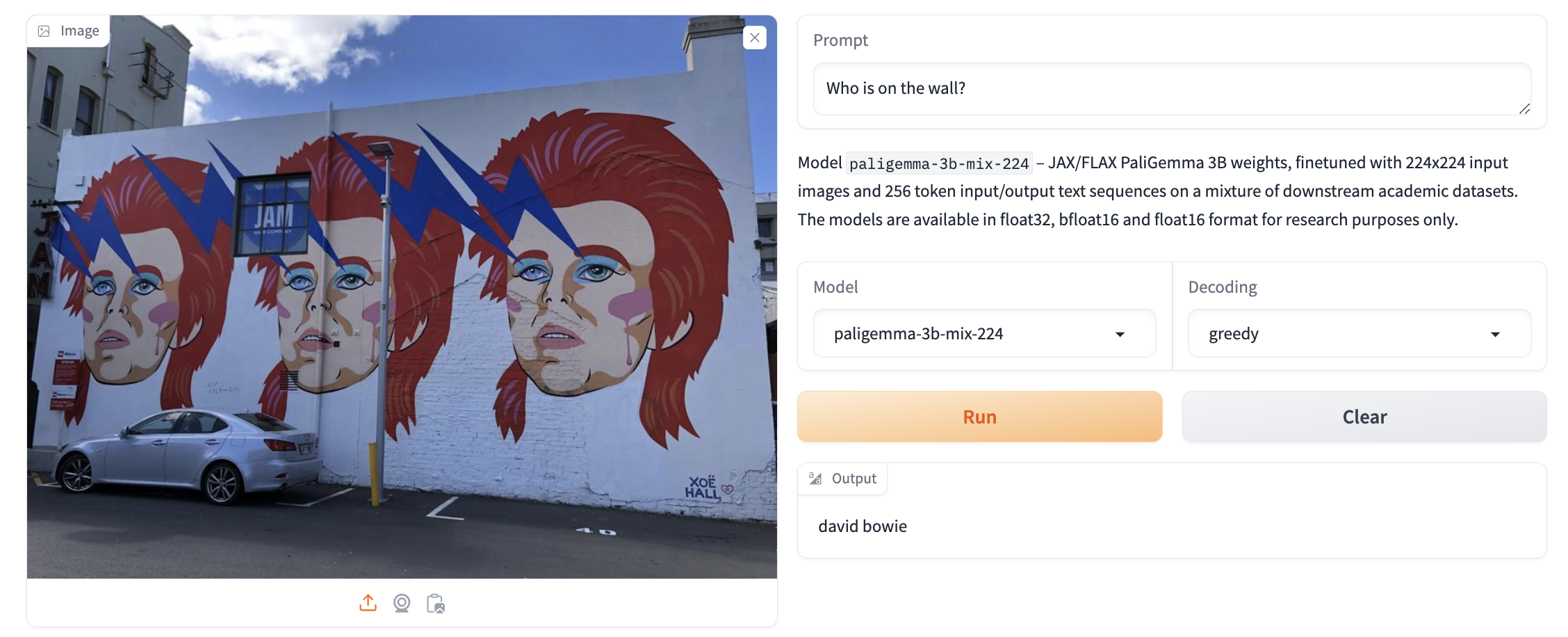
پاسخ به سوالات تصویری
PaliGemma میتواند به سوالات درباره یک تصویر پاسخ دهد، کافی است سوال خود را همراه با تصویر ارسال کنید.
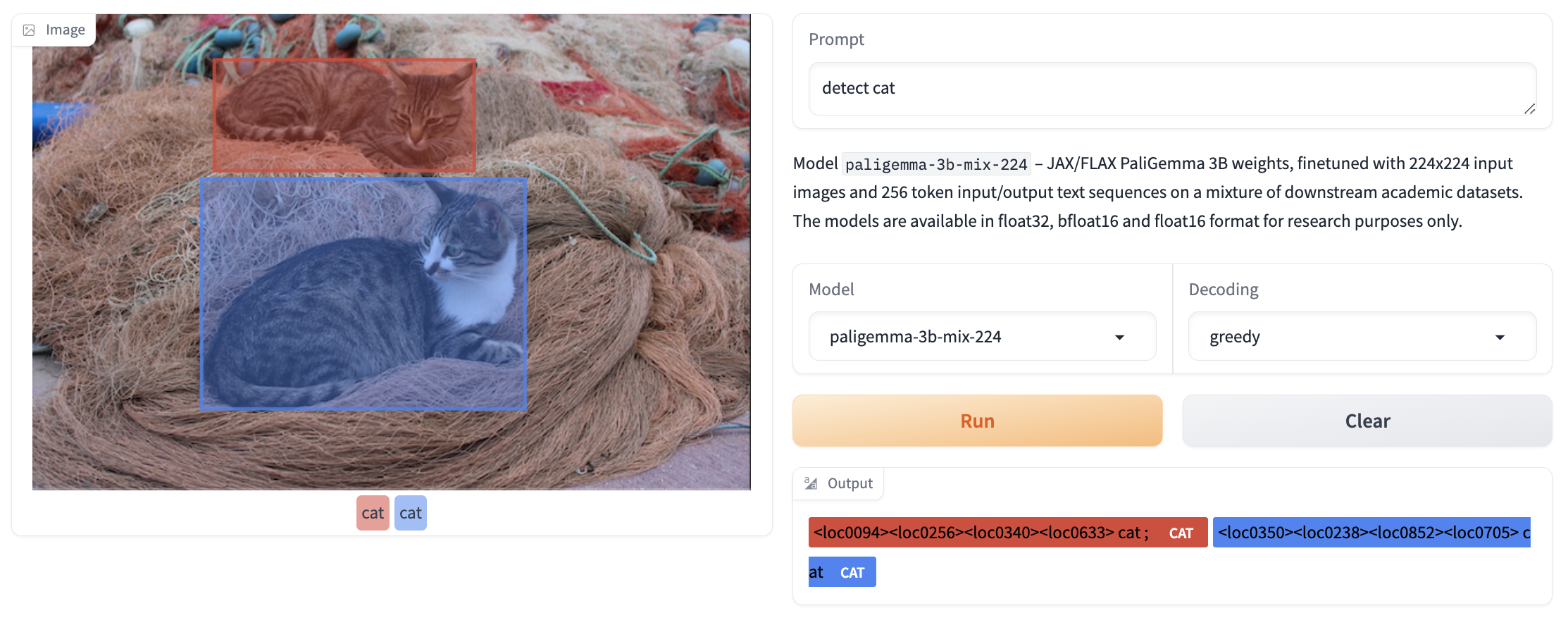
تشخیص
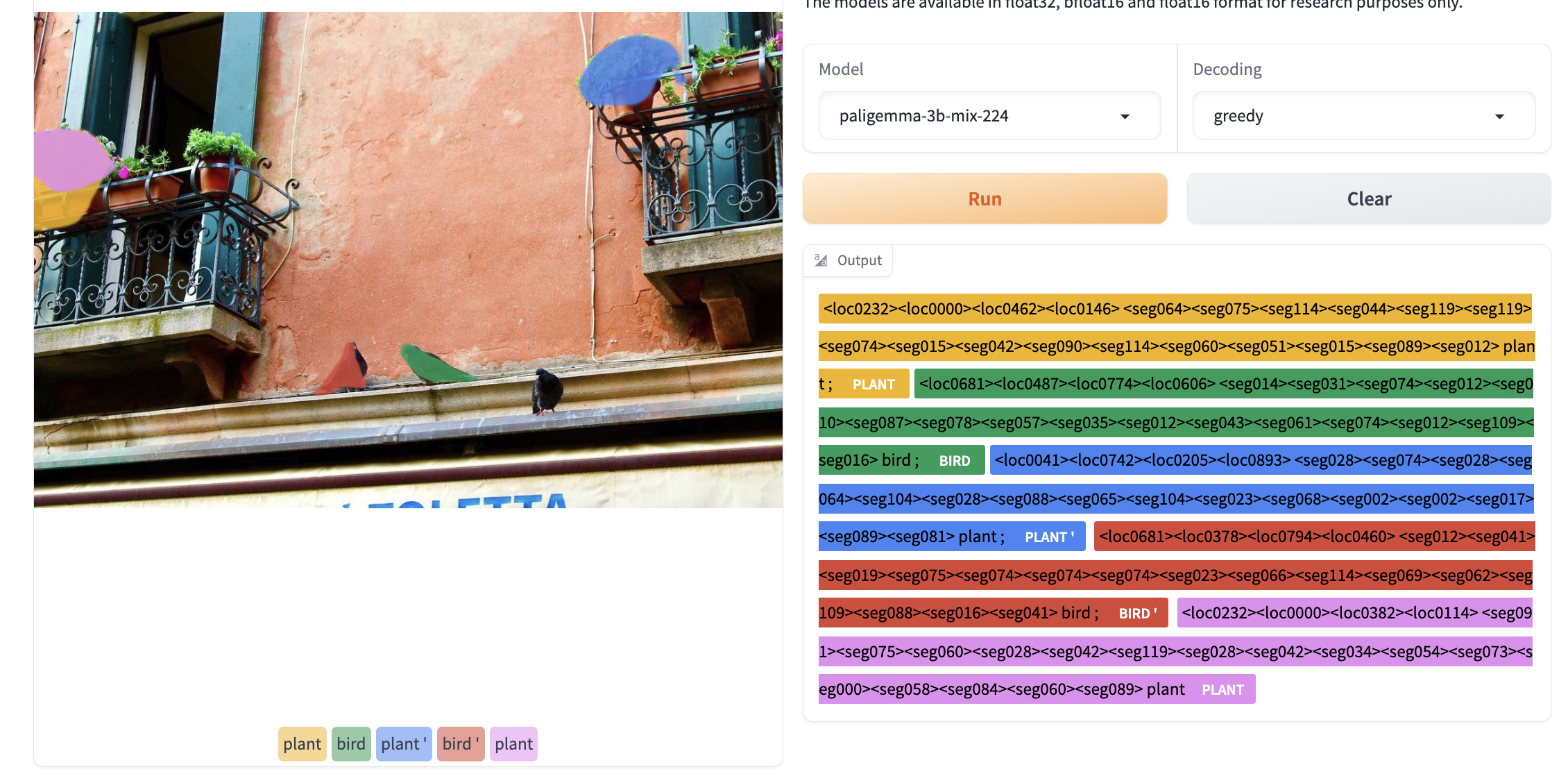
PaliGemma میتواند موجودات را در یک تصویر با استفاده از دستور تشخیص [موجود] ([entity] detect) تشخیص دهد. این مدل مکان برای مختصات جعبه محدود کننده را به صورت توکنهای ویژه <loc[value]> خروجی میدهد، جایی که value عددی است که نمایانگر یک مختصه نرمال شده است. هر تشخیص توسط چهار مختصه مکانی به ترتیب y_min, x_min, y_max, x_max نمایش داده میشود، به دنبال برچسبی که در آن جعبه تشخیص داده شده است. برای تبدیل مقادیر به مختصات، ابتدا باید اعداد را بر ۱۰۲۴ تقسیم کنید، سپس y را در ارتفاع تصویر و x را در عرض آن ضرب کنید. این کار مختصات جعبههای محدودکننده را نسبت به اندازه اصلی تصویر به شما میدهد.
قطعهبندی عبارت ارجاعی
چکپوینت PaliGemma میکس میتواند موجودات را در یک تصویر، هنگام دریافت دستور قطعهبندی [موجود] (segment [entity]) قطعهبندی کند. این کار به قطعهبندی عبارت ارجاعی معروف است، زیرا ما به موجودات مورد علاقه با توصیفات طبیعی زبان اشاره میکنیم. خروجی، دنبالهای از توکنهای مکان و قطعهبندی است. توکنهای مکان، یک جعبه محدود کننده را همانطور که در بالا توضیح داده شد، نمایش میدهند. توکنهای قطعهبندی میتوانند بیشتر پردازش شوند تا ماسکهای قطعهبندی تولید شوند.
درک اسناد
نقاط چک PaliGemma میکس قابلیتهای بسیار خوبی در فهم و استدلال اسناد دارند.
معیارهای ترکیبی
در زیر می توانید نمرات مربوط به نقاط چک ترکیبی را ببینید.
| مدل | دقت MMVP | دقت POPE (random/popular/adversarial) |
|---|---|---|
| mix-224 | 46.00 | 88.00 86.63 85.67 |
| mix-448 | 45.33 | 89.37 88.40 87.47 |
چکپوینتهای تنظیم شده
علاوه بر مدلهای پیشآموزش دیده و میکس، گوگل مدلهایی را که به وظایف مختلف منتقل شدهاند، منتشر کرده است. اینها مطابق با معیارهای علمی هستند که میتوان توسط جامعه تحقیقاتی برای مقایسه عملکرد آنها استفاده شوند. در زیر، میتوانید تعدادی از آنها را پیدا کنید. این مدلها همچنین در رزولوشنهای مختلف موجود هستند. شما میتوانید کارت مدل هر مدل را برای تمام معیارها بررسی کنید.
| مدل | مجموعه داده / وظیفه | امتیاز انجام کار محول شده |
|---|---|---|
| paligemma-3b-ft-vqav2-448 | Diagram Understanding | 85.64 Accuracy on VQAV2 |
| paligemma-3b-ft-cococap-448 | COCO Captions | 144.6 CIDEr |
| paligemma-3b-ft-science-qa-448 | Science Question Answering | 95.93 Accuracy on ScienceQA Img subset with no CoT |
| paligemma-3b-ft-refcoco-seg-896 | Understanding References to Specific Objects in Images | 76.94 Mean IoU on refcoco 72.18 Mean IoU on refcoco+ 72.22 Mean IoU on refcocog |
| paligemma-3b-ft-rsvqa-hr-224 | Remote Sensing Visual Question Answering | 92.61 Accuracy on test 90.58 Accuracy on test2 |
دمو
در فیلم کوتاه زیر، نسخهای از دمو سازگار با ترنسفورمرها آمده تا نشان دهد چگونه میتوان از API ترنسفورمرهای PaliGemma استفاده کرد. این دمو، پیادهسازی مرجع را در مخزن big_vision بستهبندی میکند و راه آسانی را برای بازی با مدلهای میکس فراهم میکند.
چگونگی اجرای استنتاج
برای دسترسی به مدلهای PaliGemma ، شما نیاز به پذیرش شرایط و ضوابط مجوز Gemma دارید. اگر قبلاً به سایر مدلهای Gemma در Hugging Face دسترسی داشتهاید، آمادهاید. در غیر این صورت، میتوانید به یکی از مدلهای PaliGemma مراجعه کنید و اگر با آن موافق هستید، مجوز را بپذیرید. پس از دسترسی، شما نیاز به احراز هویت از طریق notebook_login یا ورود به سیستم huggingface-cli دارید. پس از ورود به سیستم، آماده شروع کار خواهید بود!
شما همچنین میتوانید بلافاصله استنتاج را در این نوتبوک امتحان کنید.
استفاده از ترنسفورمرها
شما میتوانید از کلاس PaliGemmaForConditionalGeneration برای انجام استنتاج با هر یک از مدلهای منتشر شده استفاده کنید. فقط باید پرامپت و تصویر را با پردازنده داخلی پیشپردازش کنید و سپس ورودیهای پیشپردازش شده را برای تولید ارسال کنید.
from transformers import AutoProcessor, PaliGemmaForConditionalGeneration
model_id = "google/paligemma-3b-mix-224"
model = PaliGemmaForConditionalGeneration.from_pretrained(model_id)
processor = AutoProcessor.from_pretrained(model_id)
prompt = "What is on the flower?"
image_file = "https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/bee.jpg?download=true"
raw_image = Image.open(requests.get(image_file, stream=True).raw)
inputs = processor(prompt, raw_image, return_tensors="pt")
output = model.generate(**inputs, max_new_tokens=20)
print(processor.decode(output[0], skip_special_tokens=True)[len(prompt):])
# beeهمچنین میتوانید مدل را به صورت ۴ بیتی به شرح زیر بارگذاری کنید:
from transformers import BitsAndBytesConfig
bnb_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_quant_type="nf4",
bnb_4bit_compute_dtype=torch.bfloat16
)
model = PaligemmaForConditionalGeneration.from_pretrained(
model_id,
quantization_config=bnb_config,
device_map={"":0}
)علاوه بر بارگذاری ۴ بیتی (یا ۸ بیتی)، ادغام ترنسفورمرها به شما اجازه میدهد از ابزارهای دیگر در اکوسیستم Hugging Face استفاده کنید، مانند:
- اسکریپت ها و نمونه های آموزش و استنباط
- سریال سازی به فایل های امن (Safetensors)
- ادغام با ابزارهایی مانند PEFT (تنظیم دقیق پارامترها)
- ابزارهای کمکی و کمکی برای اجرای نسل با مدل
فرایند استنتاج مفصل
اگر میخواهید کد پیشپردازش یا آموزش خودتان را بنویسید یا دوست دارید جزئیات بیشتری درباره نحوه کارکرد PaliGemma بدانید، اینها مراحلی هستند که تصویر ورودی و متن از آنها عبور میکنند:
متن ورودی به صورت معمول توکنسازی میشود. یک توکن <bos> در ابتدا اضافه میشود و یک توکن جدید خط (\n) نیز اضافه میگردد. این توکن خط جدید بخش ضروری از پرامپت ورودی است که مدل با آن آموزش دیده است، بنابراین افزودن آن به صورت صریح اطمینان میدهد که همیشه حضور دارد. متن توکنسازی شده هم با تعداد مشخصی توکنهای <image> پیشوند میشود. چند تا؟ این بستگی به وضوح تصویر ورودی و اندازه قطعه (Patch) مورد استفاده توسط مدل SigLIP دارد.
مدلهای PaliGemma روی یکی از سه اندازه مربعی (224×224، 448×448، یا 896×896) آموزش دیدهاند و همیشه از اندازه قطعه 14 استفاده میکنند. بنابراین، تعداد توکنهای <image> که باید اضافه شوند برای مدلهای 224، 256 توکن است (224/14 * 224/14)، برای مدلهای 448، 1024 توکن و برای مدلهای 896، 4096 توکن است.
توجه داشته باشید که تصاویر بزرگتر منجر به دنبالههای ورودی بسیار طولانیتر میشوند و در نتیجه به حافظه بسیار بیشتری برای پردازش بخش زبانی مدل نیاز دارند. هنگام انتخاب مدلی که میخواهید استفاده کنید، این نکته را در نظر داشته باشید. برای وظایف دقیقتر، مانند OCR، تصاویر بزرگتر ممکن است به دستیابی به نتایج بهتر کمک کنند، اما افزایش کیفیت برای اکثر وظایف کوچک مقرون به صرفه نیست.
این “پرامپت” کامل از طریق لایه تعبیههای متنی مدل زبان عبور میکند و تعبیههای توکن با 2048 بعد برای هر توکن تولید میکند.
همزمان با این، تصویر ورودی با استفاده از بازنمونهگیری دوجهتی (bicubic resampling)، به اندازه ورودی مورد نیاز (224×224 برای مدلهای با کمترین وضوح) تغییر اندازه میدهد. سپس از طریق رمزگذار تصویر SigLIP عبور میکند تا تعبیههای تصویری با 1152 بعد برای هر Patch تولید کند. در اینجاست که پروژکتور خطی وارد عمل میشود: تعبیههای تصویری به منظور به دست آوردن نمایشهایی با 2048 بعد برای هر Patch، پروژه میشوند، همانند آنچه از توکنهای متنی به دست آمده است.
پس از آن، تعبیههای نهایی تصویر با تعبیههای متنی <image> ترکیب میشوند و این ورودی نهایی است که برای تولید متن خودکار به کار میرود. تولید به طور معمول در حالت خودکار پیشرونده کار میکند. این از توجه کامل بلوک برای ورودی کامل (تصویر + bos + پرامپت + \n) استفاده میکند، و از یک ماسک توجه علت ( block attention) برای متن تولید شده استفاده میکند.
تمام این جزئیات به طور خودکار در کلاسهای پردازنده و مدل تعریف شده اند، بنابراین استنباط میتواند با استفاده از API ترانسفورمرهای سطح بالا که در مثالهای قبلی نشان داده شده است، انجام گیرد.
Fine Tuning
تنظیم دقیق
استفاده از big_vision
PaliGemma در پایگاه کد big_vision آموزش دیده است. همان پایگاه کد قبلاً برای توسعه مدلهایی مانند BiT, the original ViT, LiT CapPa, SigLIP و بسیاری دیگر استفاده شده است.
پوشه پیکربندی پروژه configs/proj/paligemma/ شامل یک README.md است. مدل آموزش دیده میتواند با اجرای فایلهای پیکربندی در زیرپوشه transfers/ منتقل شود و تمام نتایج انتقال ما با اجرای پیکربندیهای ارائه شده در آن به دست آمده است. اگر میخواهید مدل خود را منتقل کنید، پیکربندی نمونه transfers/forkme.py را شاخه کنید و دستورالعملهای موجود در نظرات را دنبال کنید تا آن را به کاربرد خود تطبیق دهید.
همچنین یک Colab با نام finetune_paligemma.ipynb وجود دارد که یک تنظیم دقیق سادهشده را اجرا میکند که روی یک زمان اجرای GPU T4 رایگان کار میکند. برای متناسب ساختن با حافظه محدود میزبان و GPU، کد در Colab تنها وزنها در لایههای توجه (170M پارامتر) را بهروزرسانی میکند و از SGD (به جای Adam) استفاده میکند.
استفاده از transformers
تنظیم دقیق PaliGemma به لطف transformers بسیار آسان است و میتوان تنظیم دقیق QLoRA یا LoRA را انجام داد. در این مثال، ما به طور مختصر دیکودر را تنظیم دقیق میکنیم و سپس نحوه تغییر به تنظیم دقیق QLoRA را نشان میدهیم. نسخه آخرین کتابخانه transformers را نصب خواهیم کرد.
pip install git+https://github.com/huggingface/transformers.gitمانند بخش استنباط، ما برای دسترسی به مدل از طریق تابع notebook_login() احراز هویت خواهیم کرد.
from huggingface_hub import notebook_login
notebook_login()در این مثال، ما از دیتاست VQAv2 استفاده خواهیم کرد و مدل را برای پاسخ دادن به سوالات درباره تصاویر تنظیم دقیق میکنیم. بیایید دیتاست را بارگذاری کنیم. ما فقط از ستونهای سوال، پاسخ انتخابی و تصویر استفاده خواهیم کرد، پس بیایید بقیه ستونها را نیز حذف کنیم. همچنین دیتاست را تقسیم خواهیم کرد.
from datasets import load_dataset
ds = load_dataset('HuggingFaceM4/VQAv2', split="train")
cols_remove = ["question_type", "answers", "answer_type", "image_id", "question_id"]
ds = ds.remove_columns(cols_remove)
ds = ds.train_test_split(test_size=0.1)
train_ds = ds["train"]
val_ds = ds["test"]اکنون پردازشگر را بارگذاری میکنیم که شامل بخش پردازش تصویر و توکنسازی است و دیتاست خود را پیشپردازش میکنیم.
from transformers import PaliGemmaProcessor
model_id = "google/paligemma-3b-pt-224"
processor = PaliGemmaProcessor(model_id)ما یک الگوی پرسش را ایجاد خواهیم کرد تا PaliGemma را برای پاسخ دادن به سوالات بصری شرطی کنیم. از آنجا که توکنایزر ورودیها را پد میکند، ما باید پدها در برچسبهایمان را به چیزی غیر از توکن پد در توکنایزر تنظیم کنیم، همچنین توکن تصویر.
توجه: در بخش توکنسازی، ما پرچم tokenize_newline_separately را میگذرانیم زیرا خط جدید برای شرطیسازی پرسش استفاده میشود و باید جداگانه توکنسازی شود. در طول استنباط، این به طور پیشفرض به True تنظیم میشود.
device = "cuda"
image_token = processor.tokenizer.convert_tokens_to_ids("<image>")
def collate_fn(examples):
texts = ["answer " + example["question"] + "\n" + example['multiple_choice_answer'] for example in examples]
images = [example["image"].convert("RGB") for example in examples]
tokens = processor(text=texts, images=images,
return_tensors="pt", padding="longest",
tokenize_newline_separately=False)
labels = tokens["input_ids"].clone()
labels[labels == processor.tokenizer.pad_token_id] = -100
labels[labels == image_token] = -100
tokens["labels"] = labels
tokens = tokens.to(torch.bfloat16).to(device)
return tokensاکنون Trainer و TrainingArguments را مقداردهی اولیه می کنیم. اگر تنظیم دقیق QLoRA را انجام می دهید، به جای آن بهینه ساز را روی paged_adamw_8bit قرار دهید.
from transformers import TrainingArguments
args=TrainingArguments(
num_train_epochs=2,
remove_unused_columns=False,
per_device_train_batch_size=16,
gradient_accumulation_steps=4,
warmup_steps=2,
learning_rate=2e-5,
weight_decay=1e-6,
adam_beta2=0.999,
logging_steps=100,
optim="adamw_hf",
save_strategy="steps",
save_steps=1000,
push_to_hub=True,
save_total_limit=1,
bf16=True,
report_to=["tensorboard"],
dataloader_pin_memory=False
)Trainer را راهاندازی کنید، مجموعه دادهها، تابع جمعآوری دادهها و آرگومانهای آموزشی را ارسال کنید و برای شروع آموزش، train() را فراخوانی کنید.
trainer = Trainer(
model=model,
train_dataset=train_ds,
eval_dataset=val_ds,
data_collator=collate_fn,
args=args
)
trainer.train()
پرسشهای متداول
1. PaliGemma چیست؟
PaliGemma یک مدل پیشرفته زبان بینایی است که توسط گوگل توسعه یافته است. این مدل ترکیبی از پردازش زبان طبیعی پیشرفته با بینایی کامپیوتری است که قادر به درک و تولید توضیحات متنی بر اساس تصاویر میباشد.
2. PaliGemma چگونه کار میکند؟
PaliGemma از ترکیبی از شبکههای عصبی کانولوشنی (CNN) برای تشخیص تصاویر و ترنسفورمرها برای درک زبان استفاده میکند. این ترکیب به آن امکان میدهد محتوای بصری را تحلیل کرده و توضیحات متنی منسجم یا پاسخهایی بر اساس تصاویر تولید کند.
3. کاربردهای اصلی PaliGemma چیست؟
PaliGemma میتواند در کاربردهای مختلفی مورد استفاده قرار گیرد، از جمله:
توضیح تصویر
پاسخ به سوالات بصری
نظارت بر محتوا
فناوریهای کمکی برای افراد نابینا
قابلیتهای جستجوی پیشرفته
4. دقت PaliGemma چقدر است؟
PaliGemma به لطف آموزش بر روی دادههای گسترده شامل تصاویر متنوع و توضیحات متنی مرتبط، دقت بسیار بالایی دارد. با این حال، دقت آن میتواند بسته به پیچیدگی و زمینه تصاویر متفاوت باشد.
5. آیا PaliGemma میتواند در برنامههای موجود یکپارچه شود؟
بله، PaliGemma میتواند از طریق API های ارائه شده توسط گوگل در برنامههای موجود یکپارچه شود. این امکان به توسعهدهندگان اجازه میدهد تا از قابلیتهای آن در راهحلهای نرمافزاری خود استفاده کنند.
6. نیازمندیهای سختافزاری برای استفاده از PaliGemma چیست؟
استفاده از PaliGemma از طریق خدمات ابری گوگل معمولاً نیاز به سختافزار تخصصی در سمت کاربر ندارد. با این حال، برای استقرار در محل، توصیه میشود که از پردازندههای گرافیکی با عملکرد بالا و حافظه کافی برای مدیریت نیازهای محاسباتی استفاده شود.
7. آیا PaliGemma از چندین زبان پشتیبانی میکند؟
بله، PaliGemma از چندین زبان پشتیبانی میکند و این امر آن را برای کاربران در سراسر جهان بسیار متنوع میسازد. این مدل میتواند توضیحات تولید کرده و سوالات را در زبانهای مختلف درک کند.
8. PaliGemma چگونه حریم خصوصی و امنیت را تضمین میکند؟
گوگل برای PaliGemma تدابیر سختگیرانهای در زمینه حریم خصوصی و امنیت اجرا میکند. دادههایی که به PaliGemma ارسال و از آن دریافت میشوند رمزگذاری میشوند و گوگل از سیاستهای محافظت از دادههای قوی برای حفاظت از اطلاعات کاربران پیروی میکند.
9. آیا PaliGemma میتواند تحلیل تصاویر در زمان واقعی را انجام دهد؟
بله، PaliGemma برای انجام تحلیل تصاویر در زمان واقعی طراحی شده است، که آن را برای کاربردهایی که نیاز به بازخورد فوری دارند، مانند نظارت بر محتوای زنده و رابطهای کاربری تعاملی، مناسب میسازد.
10. چگونه میتوانم استفاده از PaliGemma را شروع کنم؟
برای شروع استفاده از PaliGemma، میتوانید به وبسایت Google Cloud مراجعه کنید و از API های موجود در آن استفاده کنید. مستندات و پشتیبانیهای دقیق برای کمک به شما در یکپارچهسازی PaliGemma در برنامههایتان در دسترس هستند.



