
مدل زبان بینایی یا Vision Language Model، مدلی است که میتواند به طور همزمان از تصاویر و متون یاد بگیرد تا به انجام وظایف مختلفی از پاسخ به سوالات بصری تا توصیف تصاویر بپردازد. در این پست، به بررسی اجزای اصلی مدلهای زبان بینایی میپردازیم؛ نگاهی کلی به آنها داریم، نحوه کار آنها را درک میکنیم، روش یافتن مدل مناسب را بررسی میکنیم، نحوه استفاده از آنها برای استنتاج را یاد میگیریم و چگونگی تنظیم دقیق آنها را با نسخه جدید trl که به تازگی منتشر شده، توضیح میدهیم. با نقطه همراه باشید.
مدل زبان بینایی چیست؟
مدلهای زبان بینایی به عنوان مدلهای چندوجهی تعریف میشوند که میتوانند از تصاویر و متن یاد بگیرند. این مدلها نوعی از مدلهای مولد (Generative) هستند که ورودی تصویر و متن را دریافت کرده و خروجی متنی تولید میکنند. مدلهای بزرگ زبان بینایی قابلیتهای خوبی در انجام وظایف، بدون نیاز به آموزش اولیه (zero-shot) دارند، به خوبی تعمیم میدهند و میتوانند با انواع مختلف تصاویر، از جمله اسناد، صفحات وب و غیره کار کنند.
کاربردهای Vision Language Model شامل گفتگو درباره تصاویر، تشخیص تصویر از طریق دستورالعملها، پاسخ به سوالات بصری، درک اسناد، توصیف تصاویر و … میشود. برخی از مدلهای زبان بینایی میتوانند مختصات مکانی در یک تصویر را نیز درک کنند. این مدلها میتوانند جعبههای محدودکننده یا ماسکهای تقسیمبندی را هنگام درخواست برای تشخیص یا تقسیمبندی موضوع خاصی تولید کنند، یا میتوانند موجودیتهای مختلف را مکانیابی کرده و به سوالاتی درباره موقعیت نسبی یا مطلق آنها پاسخ دهند. مجموعه مدلهای بزرگ زبان بینایی موجود، در دادههایی که بر آنها آموزش دیدهاند، نحوه کدگذاری تصاویر و در نتیجه قابلیتهای آنها تنوع زیادی دارند.
بیشتر بخوانید: PaliGemma مدل پیشرفته زبان بینایی گوگل
مروری بر مدلهای زبان بینایی متنباز
مدلهای زبان بینایی متنباز بسیاری در پلتفرم Hugging Face Hub وجود دارند. برخی از برجستهترین آنها در جدول زیر نشان داده شدهاند. یک دسته مدلهای پایهای وجود دارند و یک دسته مدلهایی که برای گفتگو تنظیم دقیق شدهاند و میتوان از آنها در حالت مکالمهای استفاده کرد. برخی از این مدلها دارای ویژگیای به نام “grounding” هستند که توهمات مدل را کاهش میدهد. همه مدلها بر روی زبان انگلیسی آموزش دیدهاند مگر اینکه خلاف آن ذکر شده باشد.
| مدل | مجوز | سایز مدل | وضوح تصویر | قابلیتهای اضافی |
|---|---|---|---|---|
| LLaVA 1.6 (Hermes 34B) | ✅ | 34B | 672×672 | |
| deepseek-vl-7b-base | ✅ | 7B | 384×384 | |
| DeepSeek-VL-Chat | ✅ | 7B | 384×384 | چت |
| moondream2 | ✅ | ~2B | 378×378 | |
| CogVLM-base | ✅ | 17B | 490×490 | |
| CogVLM-Chat | ✅ | 17B | 490×490 | زمینه سازی، چت |
| Fuyu-8B | ❌ | 8B | 300×300 | تشخیص متن در تصویر |
| KOSMOS-2 | ✅ | ~2B | 224×224 | زمینه سازی, تشخیص شی Zero-shot |
| Qwen-VL | ✅ | 4B | 448×448 | تشخیص شی Zero-shot |
| Qwen-VL-Chat | ✅ | 4B | 448×448 | چت |
| Yi-VL-34B | ✅ | 34B | 448×448 | دو زبانه (انگلیسی, چینی) |
یافتن مدل زبان بینایی مناسب
راههای زیادی برای انتخاب مدل مناسب برای کاربرد خاص شما وجود دارد.
Vision Arena یک جدول امتیازدهی است که به طور کامل بر اساس رأیگیری ناشناس از خروجیهای مدلها استوار است و به طور مداوم بهروزرسانی میشود. در این عرصه، کاربران یک تصویر و یک درخواست وارد میکنند و خروجیهای دو مدل مختلف به صورت ناشناس نمونهبرداری میشود، سپس کاربر میتواند خروجی مورد نظر خود را انتخاب کند. به این ترتیب، جدول امتیازدهی بهطور کامل بر اساس ترجیحات انسانی ساخته میشود.
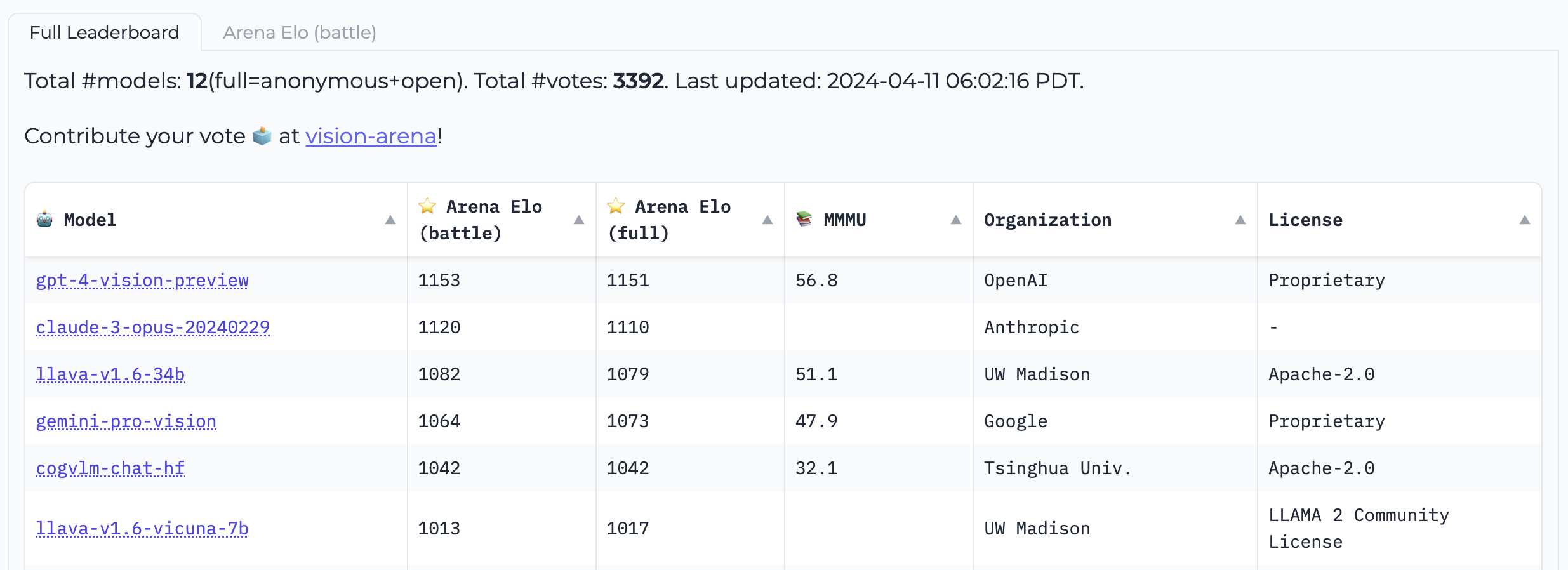
جدول امتیازات Open VLM، یک جدول امتیازات دیگر است که در آن مدلهای زبان بینایی مختلف بر اساس این معیارها و امتیازات میانگین رتبهبندی میشوند. شما میتوانید مدلها را براساس اندازه مدل، مجوزهای اختصاصی یا متنباز و رتبهبندی برای معیارهای مختلف فیلتر کنید. VLMEvalKit یک ابزار برای اجرای بنچمارک روی مدلهای زبان بینایی است که جدول امتیازات Open VLM را تغذیه میکند.
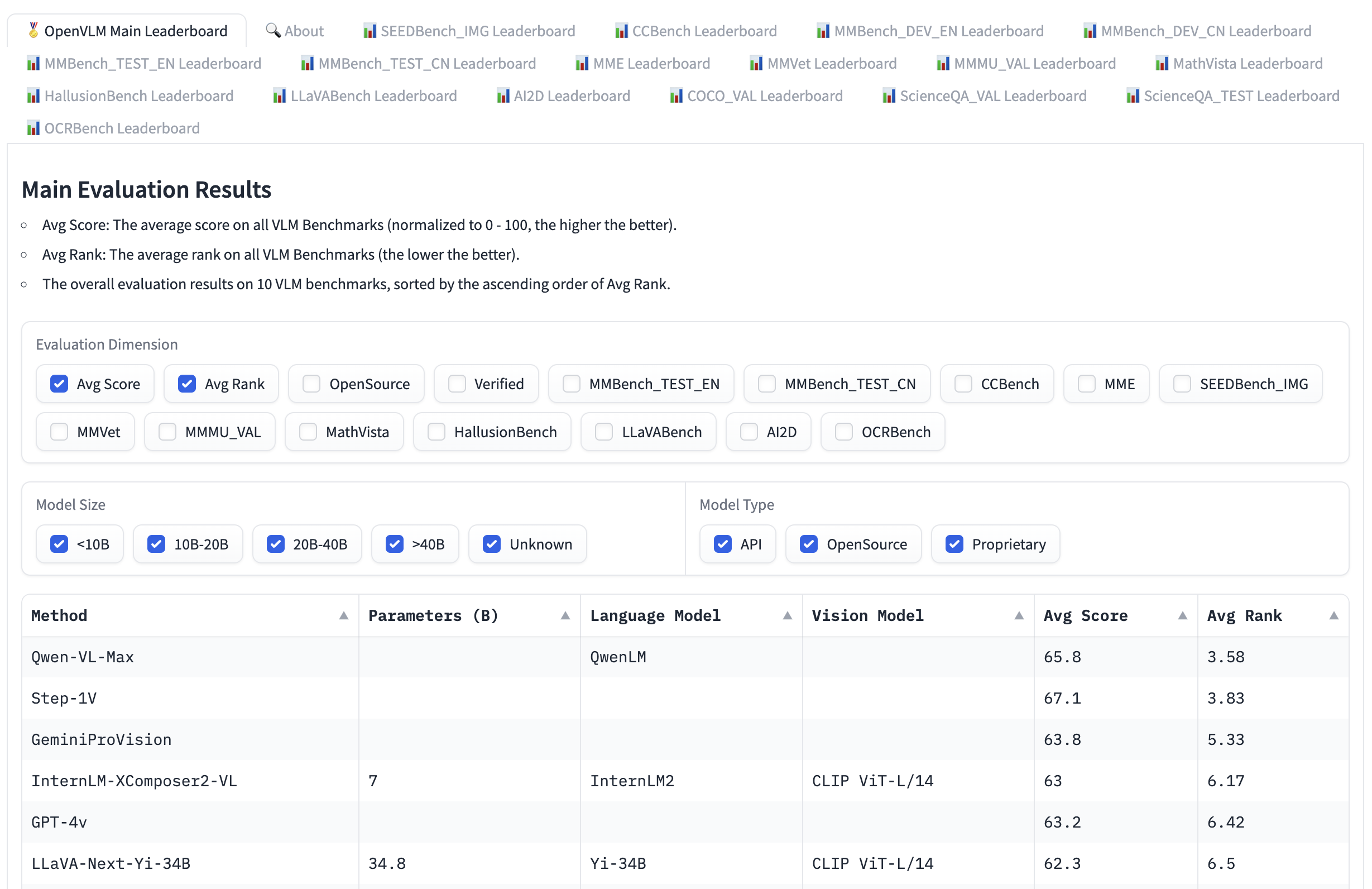
LMMS-Eval یک مجموعه ارزیابی دیگر است که یک واسط خط فرمان استاندارد برای ارزیابی مدلهای Hugging Face انتخابی شما با استفاده از دیتاستهای میزبانی شده در Hugging Face Hub فراهم میکند، مانند مثال زیر:
accelerate launch --num_processes=8 -m lmms_eval --model llava --model_args pretrained="liuhaotian/llava-v1.5-7b" --tasks mme,mmbench_en --batch_size 1 --log_samples --log_samples_suffix llava_v1.5_mme_mmbenchen --output_path ./logs/هر دوی Vision Arena و جدول امتیازات Open VLM محدود به مدلهایی هستند که به آنها ارسال شدهاند و نیاز به بهروزرسانی دارند تا مدلهای جدید اضافه شوند. اگر میخواهید مدلهای بیشتری پیدا کنید، میتوانید در Hub برای مدلهای زیر وظیفه image-text-to-text جستجو کنید.
بنچمارکهای مختلفی برای ارزیابی مدلهای زبان بینایی وجود دارند که در جداول امتیازات ممکن است با آنها مواجه شوید. در ادامه به چند مورد از آنها خواهیم پرداخت.
MMMU
MMMU (A Massive Multi-discipline Multimodal Understanding and Reasoning Benchmark for Expert AGI) جامعترین معیار برای ارزیابی مدلهای زبان بینایی است. این بنچمارک شامل ۱۱.۵ هزار چالش چندوجهی است که نیاز به دانش و استدلال در سطح دانشگاهی در رشتههای مختلف مانند هنر و مهندسی دارند.
MMBench
MMBench یک معیار ارزیابی است که شامل ۳۰۰۰ سوال چندگزینهای در ۲۰ مهارت مختلف از جمله OCR، مکانیابی اشیاء و موارد دیگر است. مقاله همچنین یک استراتژی ارزیابی به نام CircularEval را معرفی میکند، که در آن گزینههای پاسخ یک سوال به صورت مختلفی جابجا میشوند و انتظار میرود مدل در هر حالت پاسخ صحیح را بدهد. بنچمارکهای دیگری نیز در حوزههای مختلف وجود دارند، از جمله MathVista (استدلال ریاضی بصری)، AI2D (درک نمودار)، ScienceQA (پاسخ به سوالات علمی) و OCRBench (درک اسناد).
جزئیات فنی
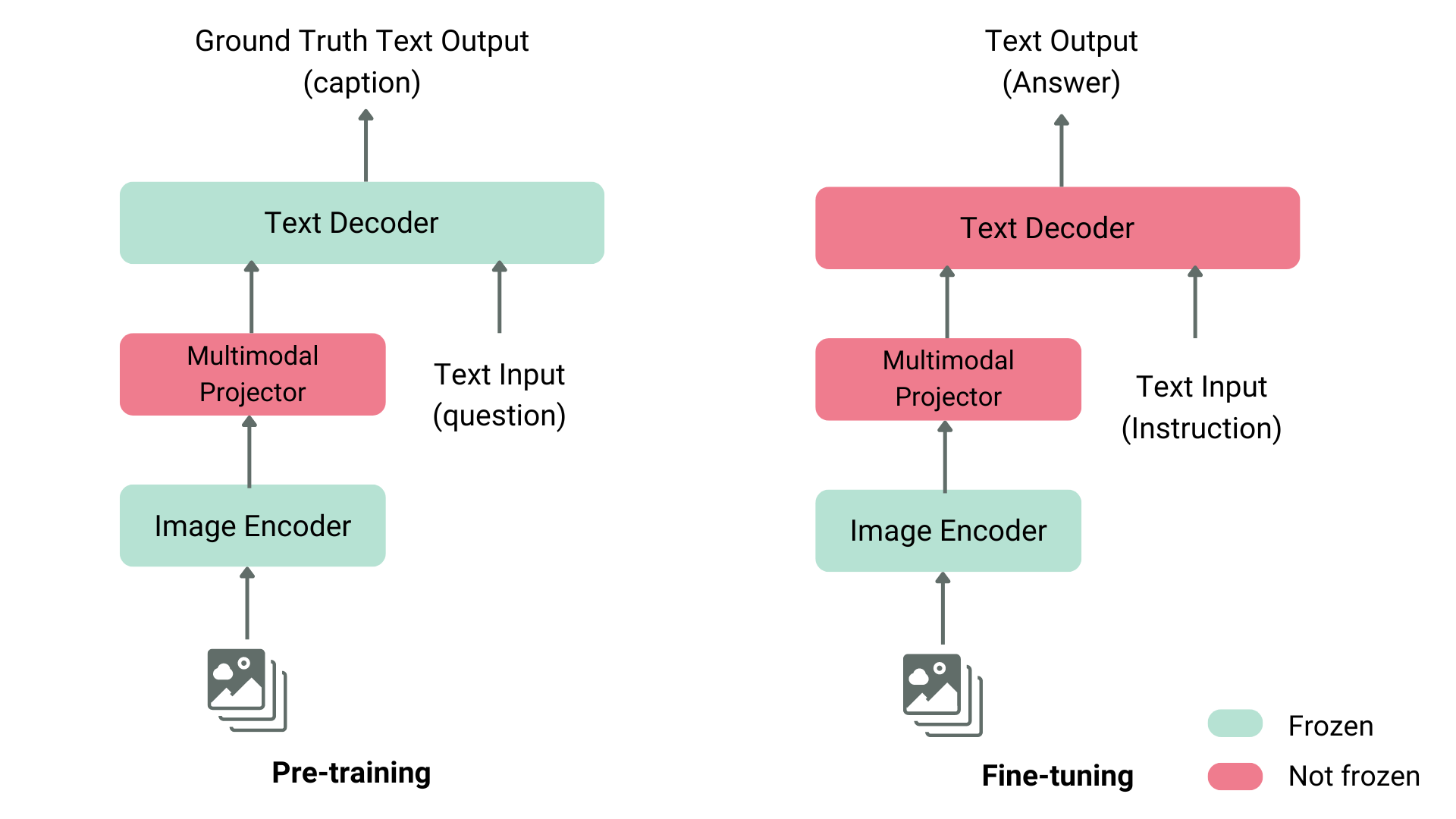
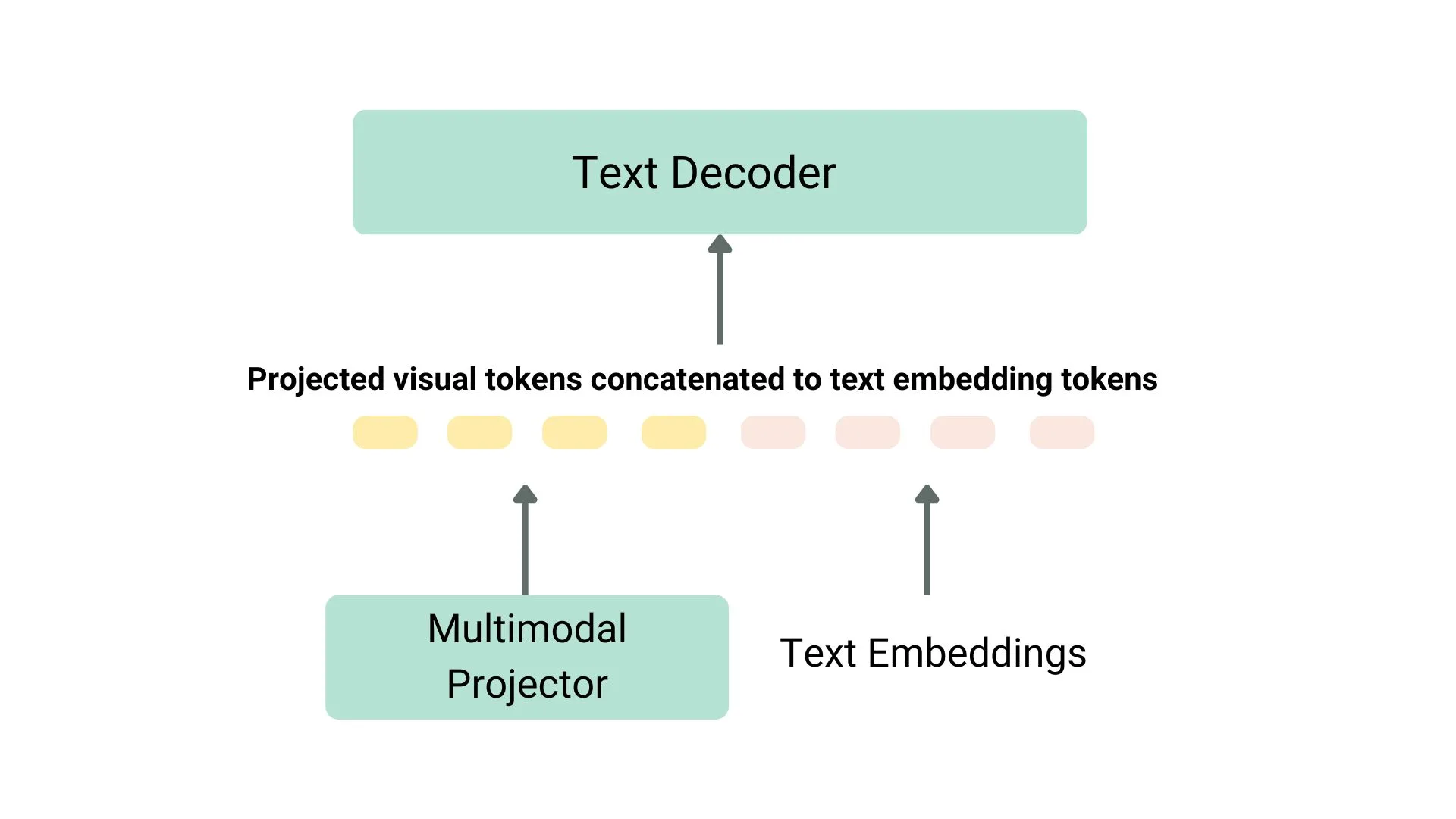
روشهای مختلفی برای پیشتمرین یک مدل زبان بینایی وجود دارد. ترفند اصلی این است که نمایش تصویر و متن را ادغام کرده و آن را به یک دکودر (decoder) متن برای تولید ورودی بدهیم. معمولترین و برجستهترین مدلها اغلب شامل یک انکودر تصویر، یک پروژکتور تعبیهسازی برای همتراز کردن نمایشهای تصویر و متن (اغلب یک شبکه عصبی چگال) و یک دیکودر متن هستند که به این ترتیب قرار گرفتهاند. در بخشهای آموزشی، مدلهای مختلف از رویکردهای مختلفی پیروی کردهاند.
به عنوان مثال، LLaVA شامل یک انکودر تصویر CLIP، یک پروژکتور چندوجهی و یک دیکودر متن Vicuna است. نویسندگان یک دیتاست از تصاویر و کپشنها را به GPT-4 دادند و سوالات مرتبط با کپشن و تصویر را تولید کردند. نویسندگان انکودر تصویر و دیکودر متن را فریز کرده و فقط پروژکتور چندوجهی را برای همتراز کردن ویژگیهای تصویر و متن آموزش دادهاند، با تغذیه مدل به تصاویر و سوالات تولید شده و مقایسه خروجی مدل با کپشنهای اصلی. پس از پیشتمرین پروژکتور، انکودر تصویر را همچنان فریز نگه داشته، دیکودر متن را از حالت فریز خارج کرده و پروژکتور را با دیکودر آموزش میدهند. این روش پیشتمرین و تنظیم دقیق، رایجترین روش آموزش مدلهای زبان بینایی است.
مثال دیگر KOSMOS-2
مثال دیگر KOSMOS-2 است، که نویسندگان آن تصمیم به آموزش کامل مدل از ابتدا تا انتها گرفتند، که این کار نسبت به پیشتمرین مشابه LLaVA هزینه محاسباتی بیشتری دارد. نویسندگان بعداً تنظیم دقیق مدل را فقط با دستورالعملهای زبانی انجام دادند تا مدل را هماهنگ کنند. Fuyu-8B، به عنوان مثال دیگری، حتی انکودر تصویر ندارد. در عوض، تکههای تصویر مستقیماً به یک لایه پروجکشن داده میشوند و سپس توالی از طریق یک دیکودر خودبازگشتی پردازش میشود.
اغلب اوقات، نیازی به پیشتمرین یک مدل زبان بینایی نیست، زیرا میتوانید از یکی از مدلهای موجود استفاده کرده یا آنها را برای کاربرد خاص خود تنظیم دقیق کنید. در ادامه به نحوهی استفاده از این مدلها با استفاده از کتابخانهی Transformers و تنظیم دقیق آنها با SFTTrainer خواهیم پرداخت.
استفاده از مدلهای زبان بینایی با Transformers
میتوانید با استفاده از مدل LlavaNext از Llava نتیجهگیری کنید، همانطور که در زیر نشان داده شده است.
ابتدا بیایید مدل و پردازشگر را مقداردهی اولیه کنیم.
from transformers import LlavaNextProcessor, LlavaNextForConditionalGeneration
import torch
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
processor = LlavaNextProcessor.from_pretrained("llava-hf/llava-v1.6-mistral-7b-hf")
model = LlavaNextForConditionalGeneration.from_pretrained(
"llava-hf/llava-v1.6-mistral-7b-hf",
torch_dtype=torch.float16,
low_cpu_mem_usage=True
)
model.to(device)اکنون تصویر و متن را به پردازنده ارسال می کنیم و سپس ورودی های پردازش شده را به تولید کننده ارسال می کنیم. توجه داشته باشید که هر مدل از الگوی سریع خود استفاده می کند، مراقب باشید که از الگوی مناسب برای جلوگیری از کاهش عملکرد استفاده کنید.
from PIL import Image
import requests
url = "https://github.com/haotian-liu/LLaVA/blob/1a91fc274d7c35a9b50b3cb29c4247ae5837ce39/images/llava_v1_5_radar.jpg?raw=true"
image = Image.open(requests.get(url, stream=True).raw)
prompt = "[INST] <image>\nWhat is shown in this image? [/INST]"
inputs = processor(prompt, image, return_tensors="pt").to(device)
output = model.generate(**inputs, max_new_tokens=100)برای رمزگشایی نشانه های خروجی، رمزگشایی را فراخوانی کنید.
print(processor.decode(output[0], skip_special_tokens=True))
تنظیم دقیق مدلهای زبان بینایی با TRL
SFTTrainer در TRL اکنون شامل پشتیبانی آزمایشی برای مدلهای زبان بینایی است! در اینجا یک مثال از نحوه انجام SFT روی Llava 1.5 VLM با استفاده از دیتاست llava-instruct که شامل ۲۶۰ هزار جفت تصویر و مکالمه است، آوردهایم. این دیتاست شامل تعاملات کاربر-دستیار است که به صورت یک توالی از پیامها قالببندی شدهاند. به عنوان مثال، هر مکالمه با یک تصویر جفت میشود که کاربر درباره آن سوال میپرسد.
برای استفاده از پشتیبانی آزمایشی آموزش VLM، باید آخرین نسخه TRL را نصب کنید، با استفاده از دستور زیر:
pip install -U trlاسکریپت کامل مثال را میتوانید اینجا پیدا کنید.
from trl.commands.cli_utils import SftScriptArguments, TrlParser
parser = TrlParser((SftScriptArguments, TrainingArguments))
args, training_args = parser.parse_args_and_config()قالب چت را برای تنظیم دقیق دستورالعمل راه اندازی کنید.
LLAVA_CHAT_TEMPLATE = """A chat between a curious user and an artificial intelligence assistant. The assistant gives helpful, detailed, and polite answers to the user's questions. {% for message in messages %}{% if message['role'] == 'user' %}USER: {% else %}ASSISTANT: {% endif %}{% for item in message['content'] %}{% if item['type'] == 'text' %}{{ item['text'] }}{% elif item['type'] == 'image' %}<image>{% endif %}{% endfor %}{% if message['role'] == 'user' %} {% else %}{{eos_token}}{% endif %}{% endfor %}"""اکنون مدل و توکنایزر خود را مقداردهی اولیه می کنیم.
from transformers import AutoTokenizer, AutoProcessor, TrainingArguments, LlavaForConditionalGeneration
import torch
model_id = "llava-hf/llava-1.5-7b-hf"
tokenizer = AutoTokenizer.from_pretrained(model_id)
tokenizer.chat_template = LLAVA_CHAT_TEMPLATE
processor = AutoProcessor.from_pretrained(model_id)
processor.tokenizer = tokenizer
model = LlavaForConditionalGeneration.from_pretrained(model_id, torch_dtype=torch.float16)بیایید یک جمعآوری داده برای ترکیب جفتهای متن و تصویر ایجاد کنیم.
class LLavaDataCollator:
def __init__(self, processor):
self.processor = processor
def __call__(self, examples):
texts = []
images = []
for example in examples:
messages = example["messages"]
text = self.processor.tokenizer.apply_chat_template(
messages, tokenize=False, add_generation_prompt=False
)
texts.append(text)
images.append(example["images"][0])
batch = self.processor(texts, images, return_tensors="pt", padding=True)
labels = batch["input_ids"].clone()
if self.processor.tokenizer.pad_token_id is not None:
labels[labels == self.processor.tokenizer.pad_token_id] = -100
batch["labels"] = labels
return batch
data_collator = LLavaDataCollator(processor)مجموعه داده را بارگیری کنید.
from datasets import load_dataset
raw_datasets = load_dataset("HuggingFaceH4/llava-instruct-mix-vsft")
train_dataset = raw_datasets["train"]
eval_dataset = raw_datasets["test"]برای شروع آموزش SFTTrainer، مدل، تقسیمبندی مجموعه دادهها، پیکربندی PEFT و تجمیعکننده داده را به عنوان ورودی به آن ارسال کنید و سپس تابع train() را فراخوانی کنید. برای ارسال نقطهبررسی نهایی خود به Hub، تابع push_to_hub() را فراخوانی کنید.
from trl import SFTTrainer
trainer = SFTTrainer(
model=model,
args=training_args,
train_dataset=train_dataset,
eval_dataset=eval_dataset,
dataset_text_field="text", # need a dummy field
tokenizer=tokenizer,
data_collator=data_collator,
dataset_kwargs={"skip_prepare_dataset": True},
)
trainer.train()مدل را ذخیره کرده و برای Hugging Face Hub بفرستید.
trainer.save_model(training_args.output_dir)
trainer.push_to_hub()
پرسشهای متداول
1. مدل زبان بینایی چیست؟
مدل زبان بینایی یک سیستم هوش مصنوعی است که میتواند تصاویر را تحلیل کرده و توضیحات متنی دقیق برای آنها تولید کند. این مدلها از تکنیکهای یادگیری عمیق استفاده میکنند تا ارتباط بین دادههای بصری و زبانی را درک کنند و بتوانند اطلاعات غنی و معناداری از تصاویر استخراج کنند.
2. چگونه مدل زبان بینایی آموزش داده میشود؟
مدلهای زبان بینایی با استفاده از مجموعههای دادههای بزرگ حاوی تصاویر و توضیحات متنی مرتبط آموزش داده میشوند. این مجموعهها معمولاً شامل میلیونها تصویر و جملات توضیحی هستند. مدل با پردازش این دادهها یاد میگیرد که ویژگیهای بصری را با کلمات و عبارات متناظر مرتبط کند.
3. کاربردهای اصلی مدل زبان بینایی چیست؟
مدلهای زبان بینایی کاربردهای گستردهای دارند، از جمله:
– تفسیر و شرح تصاویر در موتورهای جستجو
– ایجاد توضیحات متنی برای تصاویر در شبکههای اجتماعی
– کمک به افراد نابینا یا کمبینا با توصیف محیط اطراف آنها
– تحلیل و دستهبندی خودکار تصاویر در سیستمهای مدیریت محتوا
– کاربردهای امنیتی مانند شناسایی اشیاء و فعالیتها در تصاویر دوربینهای نظارتی
4. تفاوت مدل زبان بینایی با مدلهای پردازش تصویر معمولی چیست؟
مدلهای پردازش تصویر معمولی عمدتاً بر روی تشخیص و طبقهبندی اشیاء در تصاویر تمرکز دارند، در حالی که مدلهای زبان بینایی علاوه بر این، قادر به تولید توضیحات متنی پیچیده و معنادار برای تصاویر هستند. این مدلها از ترکیب شبکههای عصبی CNN برای پردازش تصویر و RNN یا Transformer برای تولید متن استفاده میکنند.
5. چالشهای اصلی در توسعه مدلهای زبان بینایی چیست؟
از جمله چالشهای اصلی میتوان به موارد زیر اشاره کرد:
– نیاز به دادههای برچسبگذاری شده بزرگ و متنوع
– پیچیدگی درک روابط بین اشیاء و مفاهیم مختلف در تصاویر
– تولید توضیحات متنی که نه تنها صحیح، بلکه روان و قابل فهم باشند
– مدیریت و کاهش تعصبات و پیشداوریهای موجود در دادههای آموزشی
6. چه الگوریتمها و تکنیکهایی در مدلهای زبان بینایی استفاده میشود؟
مدلهای زبان بینایی معمولاً از ترکیب الگوریتمهای شبکه عصبی کانولوشنی (CNN) برای استخراج ویژگیهای بصری و شبکههای عصبی بازگشتی (RNN) یا مدلهای Transformer برای تولید متن استفاده میکنند. تکنیکهایی مانند Attention Mechanism نیز برای بهبود دقت و ارتباط بین تصویر و متن به کار میروند.
7. چگونه میتوان دقت مدل زبان بینایی را ارزیابی کرد؟
دقت مدلهای زبان بینایی با استفاده از معیارهای مختلفی ارزیابی میشود، از جمله:
BLEU (Bilingual Evaluation Understudy)، که بر اساس مقایسه توضیحات تولیدی با توضیحات انسانی است.
METEOR (Metric for Evaluation of Translation with Explicit ORdering)، که دقت و همبستگی زبانی را اندازهگیری میکند.
ROUGE (Recall-Oriented Understudy for Gisting Evaluation)، که شباهت بین توضیحات تولیدی و مرجع را بررسی میکند.
CIDEr (Consensus-based Image Description Evaluation)، که بر اساس ارزیابی توافق بین توضیحات تولید شده و توضیحات مرجع است.
8. مدلهای زبان بینایی چه تاثیری بر صنعت و کسبوکارها دارند؟
مدلهای زبان بینایی میتوانند تاثیرات گستردهای بر صنعت و کسبوکارها داشته باشند، از جمله:
بهبود تجربه کاربری در پلتفرمهای آنلاین با ارائه توضیحات دقیق و مرتبط برای تصاویر
افزایش کارایی و دقت در تحلیل و دستهبندی تصاویر در سیستمهای مدیریت محتوا
فراهم کردن ابزارهای کمکی برای افراد با نیازهای ویژه
تسهیل در جستجوی بصری و پیدا کردن تصاویر مرتبط بر اساس توضیحات متنی



