
تشخیص گفتار یا automatic speech recognition، که شناخت خودکار گفتار (ASR) نیز نامیده میشود، امکان ارتباط بین انسان و ماشین را فراهم میکند. این تکنولوژی به سازمانها این قدرت را میدهد که گفتار انسان را به متن نوشتاری تبدیل کنند. تکنولوژی تشخیص گفتار میتواند بسیاری از کاربردهای تجاری از جمله خدمات مشتری، بهداشت و درمان، امور مالی و فروش را متحول کند.
در این راهنمای جامع سایت نقطه، تشخیص گفتار را توضیح خواهیم داد و نحوه کارکرد آن، الگوریتمهای مورد استفاده و کاربردهای آن در صنایع مختلف را بررسی خواهیم کرد. با ما همراه باشید!
تشخیص گفتار چیست؟
تشخیص گفتار، که به عنوان شناخت خودکار گفتار (ASR)، تبدیل گفتار به متن (STT) و تشخیص گفتار کامپیوتری نیز شناخته میشود، تکنولوژیای است که به یک کامپیوتر امکان میدهد زبان گفتاری را تشخیص داده و به متن تبدیل کند.
تکنولوژی تشخیص گفتار از مدلهای هوش مصنوعی و یادگیری ماشین استفاده میکند تا به دقت لهجهها، گویشها و الگوهای گفتاری مختلف را شناسایی و تبدیل کند.
بیشتر بخوانید: یادگیری ماشین چیست و چگونه کار می کند؟
بیشتر بخوانید: هوش مصنوعی چیست؟ آموزش AI و کاربردهای آن
ویژگیهای سیستمهای تشخیص گفتار چیست؟
سیستمهای تشخیص گفتار چندین مؤلفه دارند که با هم کار میکنند تا گفتار انسان را بفهمند و پردازش کنند. ویژگیهای کلیدی تشخیص گفتار مؤثر عبارتند از:
پیشپردازش صوتی (Audio preprocessing): پس از دریافت سیگنال خام صوتی از یک دستگاه ورودی، باید آن را پیشپردازش کنید تا کیفیت ورودی گفتار بهبود یابد. هدف اصلی پیشپردازش صوتی، گرفتن دادههای گفتاری مرتبط با حذف هر گونه اشیاء ناخواسته و کاهش نویز است.
استخراج ویژگی (Feature extraction): این مرحله سیگنال صوتی پیشپردازش شده را به یک نمایه اطلاعاتیتر تبدیل میکند. این کار دادههای خام صوتی را برای مدیریت مدلهای یادگیری ماشین در سیستمهای تشخیص گفتار، ساده تر میسازد.
وزندهی مدل زبانی (Language model weighting): وزندهی زبانی به برخی کلمات و عبارات، مانند ارجاعات محصول، در سیگنالهای صوتی و گفتاری وزن بیشتری میدهد. این باعث میشود که کلمات کلیدی در گفتار بعدی توسط سیستمهای تشخیص گفتار بیشتر شناخته شوند.
مدلسازی صوتی (Acoustic modeling): این امکان را به سیستمهای تشخیص گفتار میدهد تا واحدهای آوایی را در یک سیگنال گفتاری شناسایی و تفکیک کنند. مدلهای صوتی بر روی مجموعه دادههای بزرگی که شامل نمونههای گفتار از مجموعهای متنوع از گویندگان با لهجهها، سبکهای گفتاری و پیشینههای مختلف هستند، آموزش داده میشوند.
برچسبگذاری گوینده (Speaker labeling): این امکان را به برنامههای تشخیص گفتار میدهد تا هویت چندین گوینده را در یک ضبط صوتی تعیین کنند. این سیستم به هر گوینده در یک ضبط صوتی برچسبهای منحصربهفردی اختصاص میدهد و به این ترتیب میتوان تشخیص داد که در هر لحظه کدام گوینده در حال صحبت بوده است.
فیلتر کردن کلمات نامناسب (Profanity filtering): فرایند حذف کلمات یا عبارات توهینآمیز، نامناسب یا صریح از دادههای صوتی.

الگوریتمهای مختلف تشخیص گفتار
تشخیص گفتار از الگوریتمها و تکنیکهای محاسباتی مختلفی برای تبدیل زبان گفتاری به زبان نوشتاری استفاده میکند. در زیر برخی از روشهای معمول تشخیص گفتار آورده شده است:
مدلهای مارکوف پنهان (HMMs): مدل مارکوف پنهان یک مدل آماری مارکوف است که معمولاً در سیستمهای تشخیص گفتار سنتی استفاده میشود. HMM ها رابطه بین ویژگی های صوتی را ضبط و دینامیک زمانی سیگنال های گفتار را مدلسازی می کنند.
پردازش زبان طبیعی (NLP): NLP یک زیرشاخه از هوش مصنوعی است که بر تعامل بین انسان و ماشین از طریق زبان طبیعی تمرکز دارد. برخی از نقشهای کلیدی NLP در سیستمهای تشخیص گفتار عبارتند از:
- تخمین احتمال توالی کلمات در متن
- تبدیل عبارات محاورهای و اختصارات در زبان گفتاری به یک فرم نوشتاری استاندارد
- نگاشت واحدهای آوایی به دست آمده از مدلهای صوتی به کلمات متناظر آنها در زبان هدف
تفکیک گوینده (SD): تفکیک گوینده یا برچسبگذاری گوینده (Speaker Diarization )، فرایند شناسایی و تخصیص بخشهای گفتاری به گویندگان مربوطه آنها است. این امکان را برای تشخیص صداهای خاص گویندگان و شناسایی افراد در یک مکالمه فراهم میکند.
بیشتر بخوانید: پردازش زبان طبیعی چیست؟ همه چیز درباره NLP
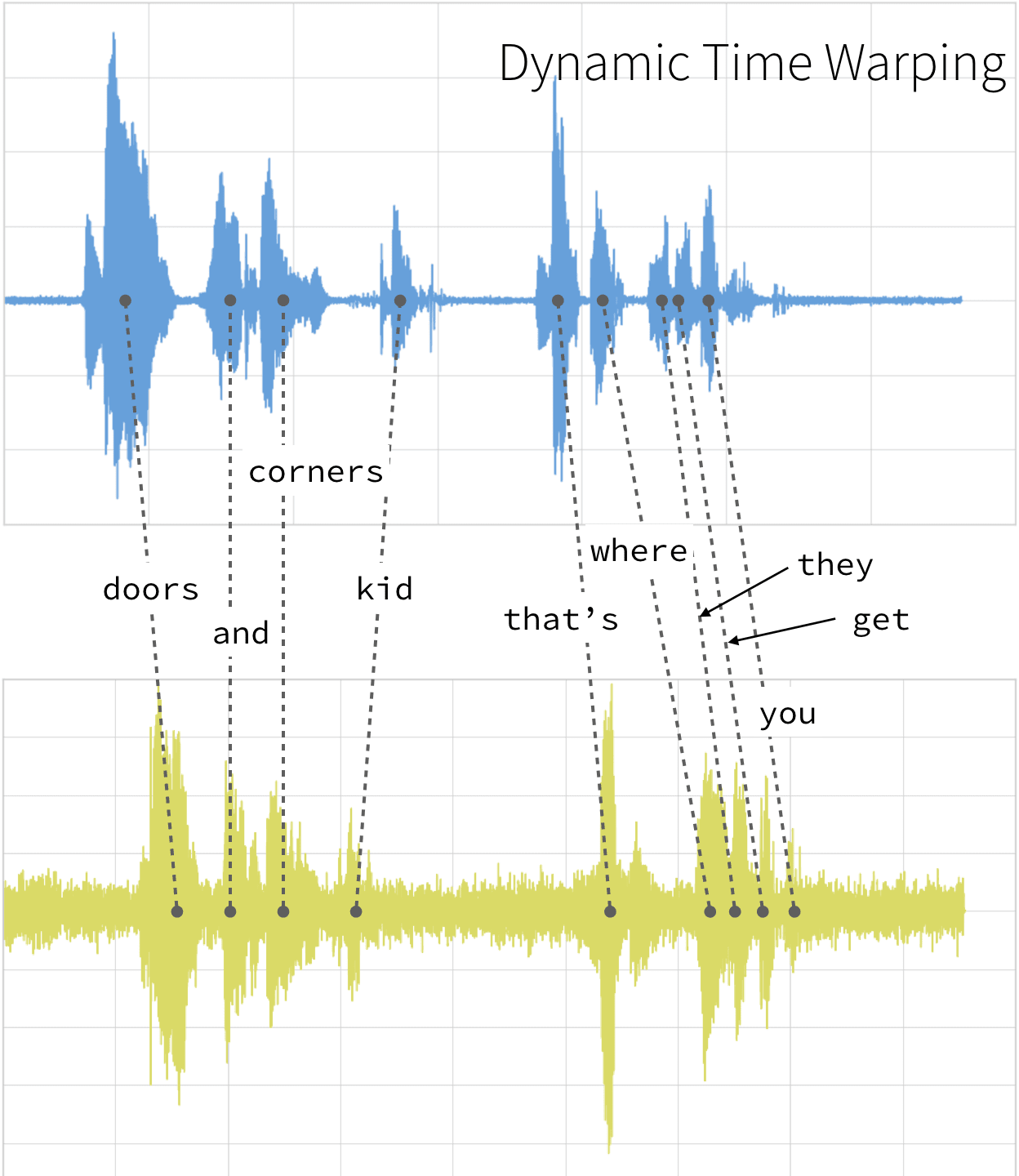
تطبیق زمانی پویا (DTW): الگوریتمهای تشخیص گفتار از الگوریتم تطبیق زمانی پویا (DTW) برای یافتن همترازی بهینه بین دو دنباله استفاده میکنند
در شکل زیر مثالی از یک تشخیص دهنده گفتار با استفاده از تطبیق زمانی پویا برای تعیین فاصله بهینه بین عناصر آمده است:
شبکههای عصبی عمیق: شبکههای عصبی با شبیهسازی ادراک فرکانس غیرخطی سیستم شنوایی انسان، دادههای ورودی را پردازش و تبدیل میکنند.
طبقهبندی زمانی اتصالی (CTC): Connectionist Temporal Classification یک هدف آموزشی است که توسط الکس گریوز در سال ۲۰۰۶ معرفی شد. CTC به ویژه برای وظایف برچسبگذاری دنبالهای و سیستمهای تشخیص گفتار انتها به انتها مفید (end-to-end) است. این امکان را به شبکه عصبی میدهد تا رابطه بین قابهای ورودی را کشف کرده و قابهای ورودی را با برچسبهای خروجی همتراز کند.
تشخیص گفتار در مقابل تشخیص صدا
تشخیص گفتار اغلب با تشخیص صدا اشتباه گرفته میشود، اما به مفاهیم متمایزی اشاره دارند. تشخیص گفتار، کلمات گفتاری را به متن نوشتاری تبدیل میکند و بر شناسایی کلمات و جملات گفته شده توسط کاربر، بدون توجه به هویت گوینده تمرکز دارد.
از طرف دیگر، تشخیص صدا به شناسایی یا تأیید صدای گوینده میپردازد و هدف آن تعیین هویت یک گوینده ناشناس است، نه تمرکز بر درک محتوای گفتار.
چالشهای تشخیص گفتار و راهحلها
در حالی که تکنولوژی تشخیص گفتار مزایای زیادی دارد، اما با برخی چالشها نیز مواجه است که نیاز به حل شدن دارند. برخی از محدودیتهای اصلی تشخیص گفتار عبارتند از:
چالشهای صوتی
1- لهجهها و گویشها
لهجهها و گویشها در تلفظ، واژگان و دستور زبان متفاوت هستند که این امر تشخیص گفتار را برای برنامهها دشوار میکند.
فرض کنید یک مدل تشخیص گفتار به طور عمده بر روی لهجههای انگلیسی آمریکایی آموزش دیده باشد. اگر یک گوینده با لهجه اسکاتلندی از سیستم استفاده کند، ممکن است به دلیل تفاوتهای تلفظ دچار مشکل شود. به عنوان مثال، کلمه “آب” در هر دو لهجه به طور متفاوتی تلفظ میشود. اگر سیستم با این تلفظ آشنا نباشد، ممکن است در تشخیص کلمه “آب” مشکل پیدا کند.
2- نویز پسزمینه
چالش: نویز پسزمینه (مثلاً ترافیک، مکالمات متقاطع) تشخیص گفتار را دشوار میکند.
چالشهای زبانی
1- کلمات خارج از واژگان
از آنجا که مدل تشخیص گفتار بر روی کلمات خارج از واژگان (OOV) آموزش ندیده است، ممکن است این کلمات را اشتباه تشخیص دهد یا نتواند آنها را در هنگام مواجهه به درستی بنویسد.
نرخ خطای کلمه (WER) یک معیار معمول است که برای اندازهگیری دقت یک سیستم تشخیص گفتار یا ترجمه ماشینی استفاده میشود.
2- همآواها
همآواها کلماتی هستند که به طور یکسان تلفظ میشوند اما معانی متفاوتی دارند، مانند “to”، “too” و “two”.
چالشهای فنی/سیستمی
1- حریم خصوصی و امنیت دادهها
سیستمهای تشخیص گفتار شامل پردازش و ذخیرهسازی اطلاعات حساس و شخصی، مانند اطلاعات مالی میشوند. یک طرف غیرمجاز میتواند از اطلاعات ضبط شده استفاده کند و منجر به نقض حریم خصوصی شود.
2- دادههای آموزشی محدود
دادههای آموزشی محدود به طور مستقیم بر عملکرد نرمافزار تشخیص گفتار تأثیر میگذارد. با دادههای آموزشی ناکافی، مدل تشخیص گفتار ممکن است در تعمیمدادن لهجههای مختلف یا شناسایی کلمات کمتر رایج، دچار مشکل شود.

۱۳ کاربرد و استفاده از تشخیص گفتار
در این بخش، توضیح خواهیم داد که تشخیص گفتار چگونه چشمانداز ارتباطات را در صنایع مختلف متحول میکند و نحوه تعامل کسبوکارها با ماشینها را تغییر میدهد.
خدمات و پشتیبانی مشتری
سیستمهای پاسخ صوتی تعاملی
پاسخ صوتی تعاملی (Interactive Voice Response) یک فناوری است که فرایند هدایت تماسگیرندگان به بخشهای مناسب را خودکار میکند. این فناوری سوالات مشتریان را میفهمد و تماسها را به بخشهای مربوطه هدایت میکند. این امر حجم تماسها برای مراکز تماس را کاهش میدهد و زمان انتظار را به حداقل میرساند.
سیستمهای IVR با استفاده از پیامهای از پیش ضبط شده یا فناوری تبدیل متن به گفتار، به سوالات ساده مشتریان بدون نیاز به دخالت انسان پاسخ میدهند. تشخیص گفتار خودکار (ASR) به سیستمهای IVR اجازه میدهد تا سوالات و شکایات مشتریان را در زمان واقعی درک و پاسخ دهند.

اتوماسیون پشتیبانی مشتری و چتباتها
طبق یک نظرسنجی، ۷۸٪ از مصرفکنندگان در سال ۲۰۲۲ با یک چتبات تعامل داشتهاند، اما ۸۰٪ از پاسخدهندگان گفتهاند که استفاده از چتباتها سطح ناامیدی آنها را افزایش داده است!
تحلیل احساسات و نظارت بر تماسها
فناوری تشخیص گفتار محتوای گفتاری یک تماس را به متن تبدیل میکند. پس از فرایند تبدیل گفتار به متن، تکنیکهای پردازش زبان طبیعی (NLP) ، متن را تحلیل کرده و به مکالمه یک امتیاز احساساتی اختصاص میدهند، مثل مثبت، منفی یا خنثی. با ادغام تشخیص گفتار با تحلیل احساسات، سازمانها میتوانند به مسائل زودتر رسیدگی کرده و اطلاعات ارزشمندی در مورد نیاز و ترجیح مشتریان کسب کنند.
پشتیبانی چندزبانه
نرمافزار تشخیص گفتار میتواند در زبانهای مختلف آموزش داده شود تا زبان گفتاری کاربر را به درستی شناسایی و نوشتار کند. با ادغام فناوری تشخیص گفتار در چتباتها و سیستمهای پاسخ صوتی تعاملی (IVR)، سازمانها میتوانند موانع زبانی را از بین برده و به مخاطبان جهانی دسترسی پیدا کنند. چتباتها و IVRهای چندزبانه به طور خودکار زبان گفتاری یک کاربر را تشخیص داده و به مدل زبانی مناسب تغییر میدهند.
احراز هویت مشتری با بیومتریک صوتی
بیومتریک صوتی از فناوریهای تشخیص گفتار برای تحلیل صدای گوینده و استخراج ویژگیهایی مانند لهجه و سرعت صحبت کردن برای تأیید هویت استفاده میکند.
فروش و بازاریابی
دستیارهای مجازی فروش
دستیارهای مجازی فروش، چتباتهای مبتنی بر هوش مصنوعی هستند که به مشتریان در خرید کمک کرده و از طریق تعاملات صوتی با آنها ارتباط برقرار میکنند. تشخیص گفتار به دستیارهای مجازی فروش اجازه میدهد تا زبان گفتاری را درک کرده و پاسخهای خود را بر اساس ترجیحات مشتری تنظیم کنند.
خدمات رونویسی
نرمافزار تشخیص گفتار، صداهای ضبط شده از تماسهای فروش و جلسات را ضبط کرده و سپس کلمات گفتاری را با استفاده از الگوریتمهای تبدیل گفتار به متن، به متن نوشتاری تبدیل میکند.
صنعت خودرو
کنترلهای فعالشونده با صدا
کنترلهای فعالشونده با صدا (Voice-activated controls) به کاربران اجازه میدهند تا با استفاده از فرمانهای صوتی با دستگاهها و برنامهها تعامل کنند. رانندگان میتوانند ویژگیهایی مانند کنترل دما، تماسهای تلفنی یا سیستمهای ناوبری را کنترل کنند.
ناوبری با کمک صدا
ناوبری با کمک صدا (Voice-assisted navigation) از ورودی صوتی راننده برای مقصد استفاده کرده و دستورالعملهای هدایتشده صوتی در زمان واقعی ارائه میدهد. رانندگان میتوانند بهروزرسانیهای ترافیکی در زمان واقعی یا جستجوی نقاط مورد علاقه اطراف محل را با استفاده از فرمانهای صوتی، بدون نیاز به کنترلهای فیزیکی درخواست کنند.

بهداشت و درمان
رونویسی پزشکی
رونویسی پزشکی (Medical transcription)، که به آن MT نیز گفته میشود، فرایند تبدیل گزارشهای پزشکی ضبط شده صوتی به یک سند نوشتاری است. مراحل اصلی در فرایند رونویسی پزشکی عبارتند از:
- ضبط صحبتهای پزشک
- رونویسی صدای ضبط شده به متن نوشتاری با استفاده از فناوری تشخیص گفتار
- ویرایش متن رونویسیشده برای دقت بیشتر و تصحیح خطاها در صورت نیاز
- قالببندی سند مطابق با الزامات قانونی و پزشکی.
دستیارهای مجازی پزشکی
دستیارهای مجازی پزشکی (Virtual medical assistants) از تشخیص گفتار، پردازش زبان طبیعی و الگوریتمهای یادگیری ماشین استفاده میکنند تا از طریق صدا یا متن با بیماران ارتباط برقرار کنند. نرمافزار تشخیص گفتار به VMAs اجازه میدهد تا به فرمانهای صوتی پاسخ دهند، اطلاعات را از پروندههای الکترونیک سلامت (EHR) بازیابی کنند و فرایند رونویسی پزشکی را خودکار کنند.
یکپارچهسازی پروندههای الکترونیک سلامت
متخصصان بهداشت و درمان میتوانند از فرمانهای صوتی برای ناوبری در سیستم پروندههای الکترونیک سلامت (Electronic Health Records)، دسترسی به دادههای بیمار و ورود دادهها به فیلدهای خاص استفاده کنند.
فن آوری
عوامل مجازی
عاملهای مجازی از پردازش زبان طبیعی (NLP) و فناوریهای تشخیص گفتار برای درک زبان گفتاری و تبدیل آن به متن استفاده میکنند. تشخیص گفتار، عوامل مجازی را قادر می سازد تا زبان گفتاری را در زمان واقعی پردازش کنند و به دستورات صوتی کاربر به سرعت و دقت پاسخ دهند.
پرسشهاس متداول
تشخیص گفتار چیست؟
تشخیص گفتار (Speech Recognition) فناوری است که گفتار انسان را به متن تبدیل میکند. این فناوری معمولاً در دستگاههای هوشمند، نرمافزارهای ترجمه و دستیارهای صوتی استفاده میشود.
تشخیص گفتار چگونه کار میکند؟
تشخیص گفتار با استفاده از الگوریتمهای یادگیری ماشین و شبکههای عصبی عمیق، صداهای ورودی را پردازش کرده و الگوهای صوتی را به کلمات و جملات تبدیل میکند.
چه کاربردهایی برای تشخیص گفتار وجود دارد؟
کاربردهای تشخیص گفتار شامل دستیارهای صوتی مانند Siri و Google Assistant، سیستمهای تبدیل گفتار به متن، تماسهای تلفنی خودکار، و نرمافزارهای ترجمه زبان میباشد.
تشخیص گفتار چه مزایایی دارد؟
از مزایای تشخیص گفتار میتوان به افزایش دسترسیپذیری برای افراد ناتوان، راحتی و سرعت در ورود اطلاعات، و بهبود تعامل انسان و ماشین اشاره کرد.
آیا تشخیص گفتار به تمام زبانها قابل استفاده است؟
تشخیص گفتار به طور گسترده برای زبانهای اصلی مانند انگلیسی، اسپانیایی، و چینی توسعه یافته است، اما برای زبانهای کمتر رایج، ممکن است دقت کمتری داشته باشد.
چگونه میتوان دقت تشخیص گفتار را افزایش داد؟
دقت تشخیص گفتار میتواند با استفاده از مدلهای آموزشی بزرگتر، بهبود کیفیت میکروفون، کاهش نویز محیط، و بهینهسازی الگوریتمها افزایش یابد.
آیا تشخیص گفتار همیشه دقیق است؟
خیر، دقت تشخیص گفتار ممکن است تحت تأثیر عواملی مانند نویز پسزمینه، لهجههای مختلف، و کیفیت صدای ورودی قرار گیرد.
آیا تشخیص گفتار میتواند برای امنیت مورد استفاده قرار گیرد؟
بله، تشخیص گفتار میتواند برای کاربردهایی مانند احراز هویت صوتی و امنیت بیومتریک استفاده شود، اما باید با سایر روشهای امنیتی ترکیب شود.
آیا تشخیص گفتار نیاز به اتصال به اینترنت دارد؟
بسیاری از سیستمهای تشخیص گفتار نیاز به اتصال به اینترنت دارند تا بتوانند از سرورهای قدرتمند برای پردازش استفاده کنند، اما برخی از سیستمهای آفلاین نیز وجود دارند.
چگونه میتوان یک سیستم تشخیص گفتار را پیادهسازی کرد؟
برای پیادهسازی یک سیستم تشخیص گفتار، میتوان از کتابخانهها و ابزارهای مختلفی مانند Google Cloud Speech-to-Text، IBM Watson، و Microsoft Azure استفاده کرد. همچنین، نیاز به دادههای آموزشی مناسب و تنظیم دقیق مدلها است.



