
مهندسی پرامپت، هنر و دانش طراحی دستورالعملهای دقیق برای مدلهای زبانی بزرگ (LLM) است تا بهترین پاسخها را از آنها دریافت کنیم. این رشته نوپا، به ما کمک میکند تا با مدلهای هوش مصنوعی به زبان خودشان صحبت کنیم و از تواناییهای آنها در زمینههای مختلف، از پاسخ دادن به سوالات ساده تا حل مسائل پیچیده، بهرهمند شویم.
با یادگیری مهندسی پرامپت، نه تنها درک عمیقتری از کارکرد مدلهای زبانی پیدا میکنیم، بلکه میتوانیم عملکرد آنها را بهبود بخشیده و کاربردهای جدیدی برای آنها بیابیم. این مهارت برای پژوهشگران، توسعهدهندگان و هر کسی که با هوش مصنوعی سر و کار دارد، بسیار مفید است.
این راهنما به عنوان یک مرجع کامل برای علاقهمندان به مهندسی پرامپت طراحی شده است. در این مقاله از نقطه، شما با جدیدترین تکنیکهای طراحی پرامپت، آموزشهای گام به گام، راهکارهای اختصاصی برای مدلهای مختلف و همچنین منابع و ابزارهای مفید آشنا خواهید شد. هدف ما این است که شما را به یک متخصص در این حوزه تبدیل کنیم تا بتوانید از تمام پتانسیل مدلهای زبانی بزرگ بهرهمند شوید.
بیشتر بخوانید:
۵ ترفند برای نوشتن پرامپتهای ChatGPT – تکنیکهایی برای استفاده بهتر از هوش مصنوعی
تنظیمات LLM
هنگام طراحی و تست پرامپتها، معمولاً از طریق یک API با LLM تعامل دارید. API یا Application Programming Interface، یک پل ارتباطی بین نرمافزارهای مختلف است که به توسعهدهندگان اجازه میدهد تا بدون نیاز به دانش عمیق از ساختار داخلی یک نرمافزار، از امکانات آن استفاده کنند.
با API میتوانید چندین پارامتر را تنظیم کنید تا نتایج مختلفی برای پرامپتهای خود بدست آورید. تنظیم این پارامترها برای بهبود صحت و قابلیت اطمینان پاسخها مهم است و اغلب نیاز به انجام یک سری آزمایش هست تا تنظیمات مناسب برای موارد استفاده خود را بیابید. در زیر تنظیمات معمولی را که هنگام استفاده از ارائهدهندگان مختلف مدلهای زبانی بزرگ با آنها مواجه خواهید شد، آوردهایم:
Temperature (دما) – به طور خلاصه، هر چه دما پایینتر باشد، نتایج تعیین شدهتر هستند؛ به این معنا که همیشه محتملترین توکن بعدی انتخاب میشود. افزایش دما میتواند به تصادفیتر شدن منجر شود که خروجیهای متنوع تر یا خلاقانه تری را تولید میکند؛ اساساً وزن توکنهای ممکن دیگر را افزایش میدهید.
Top P – یک تکنیک نمونهگیری با استفاده از دما به نام نمونهگیری هستهای است که با استفاده از آن شما میتوانید کنترل کنید مدل چقدر تعیینکننده یا قطعی باشد. اگر به دنبال پاسخهای دقیق و واقعی هستید، این مقدار را پایین نگه دارید اما اگر به دنبال پاسخهای متنوع تر هستید، مقدارش را افزایش دهید. اگر از Top P استفاده کنید به این معناست که تنها توکنهایی که تشکیلدهنده توده احتمال top_p هستند، برای پاسخها در نظر گرفته میشوند، بنابراین یک مقدار پایین top_p پاسخهای مطمئنتر را انتخاب میکند. این به این معناست که یک مقدار بالا top_p به مدل اجازه میدهد به توکنهای ممکن بیشتری نگاه کند، از جمله آنهایی که کمتر محتمل هستند، که به خروجیهای متنوعتر منجر میشود.
توصیه کلی این است که یا دما یا Top P را تغییر دهید اما هر دو را خیر.
Max Length – شما میتوانید تعداد توکنهایی که مدل تولید میکند را با تنظیم max length مدیریت کنید. تعیین یک max length به شما کمک میکند از پاسخهای طولانی یا غیرمرتبط جلوگیری کنید و هزینهها را کنترل کنید.
Stop Sequences – یک دنباله توقف یک رشته است که مدل را از تولید توکنها متوقف میکند. تعیین دنبالههای توقف یکی دیگر از راههای کنترل طول و ساختار پاسخ مدل است. به عنوان مثال، میتوانید به مدل بگویید که فهرستهایی با بیش از ۱۰ مورد تولید نکند با افزودن “۱۱” به عنوان دنباله توقف.
Frequency Penalty – جریمه فرکانس یک جریمه بر روی توکن بعدی اعمال میکند که متناسب با تعداد دفعاتی که آن توکن قبلاً در پاسخ و پرامپت ظاهر شده است. هرچه جریمه فرکانس بالاتر باشد، احتمال کمتری وجود دارد که یک کلمه دوباره ظاهر شود. این تنظیم، تکرار کلمات در پاسخ مدل را با اعمال جریمه بالاتر بر توکنهایی که بیشتر ظاهر میشوند کاهش میدهد.
Presence Penalty – جریمه حضور نیز بر روی توکنهای تکراری اعمال میشود اما برخلاف جریمه فرکانس، جریمه برای همه توکنهای تکراری یکسان است. یک توکن که دو بار ظاهر میشود و یک توکن که ۱۰ بار ظاهر میشود به طور یکسان جریمه میشوند. این تنظیم از تکرار بیش از حد عبارات در پاسخ مدل جلوگیری میکند. اگر میخواهید مدل متن متنوع یا خلاقانهای تولید کند، می توانید از جریمه حضور بالاتری استفاده کنید؛ اما اگر نیاز دارید مدل متمرکز بماند، سعی کنید از جریمه حضور پایینتری استفاده کنید.
مشابه temperature و top_p، توصیه کلی این است که جریمه فرکانس یا جریمه حضور را تغییر دهید اما هر دو با هم را خیر.
قبل از شروع با چند مثال ساده، به یاد داشته باشید که نتایج شما ممکن است بسته به نسخه مدل زبانی بزرگ که استفاده میکنید متفاوت باشد.
اصول پرامپت نویسی
پرامپت نویسی با یک مدل زبانی بزرگ
با پرامپتهای ساده، میتوانید کارهای بزرگی انجام دهید. اما اگر میخواهید بهترین نتیجه را بگیرید، باید به مدل اطلاعات دقیق و ساختارمند بدهید. پرامپت شما میتواند یک دستور ساده، یک سوال پیچیده یا ترکیبی از هر دو باشد. با افزودن جزئیات بیشتر مثل مثالها، زمینه و ورودیهای خاص، میتوانید به مدل کمک کنید تا دقیقا همان چیزی را تولید کند که میخواهید. اینجاست که جادوی پرامپت نویسی خودش را نشان میدهد!
بیایید با مرور دو مثال از یک پرامپت ساده، یکی به انگلیسی و دیگری به فارسی شروع کنیم:
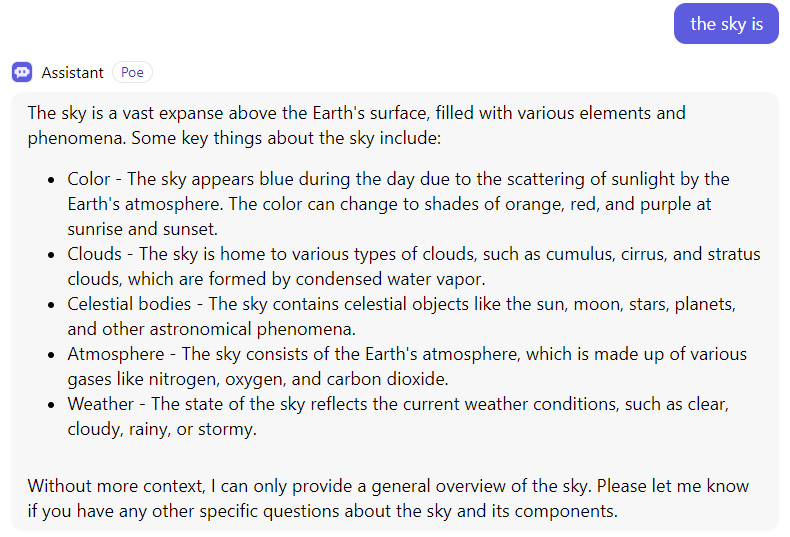
گرچه هوش مصنوعی در پاسخ، برخی توضیحات ارائه داد اما در نهایت از من خواست تا اطلاعات دقیقتری درباره موضوع مورد پرسش یعنی آسمان ارائه دهم. در این شرایط، میتوان پرسید:
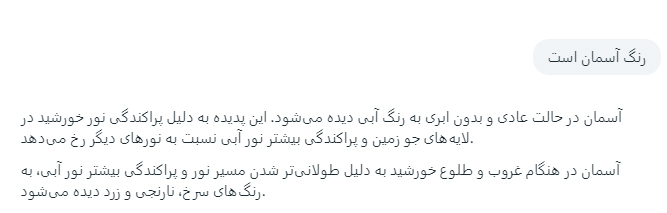
با پرامپت بالا شما به مدل می فهمانید که موضوع پرسش تان دقیقا چیست؛ بنابراین نتیجه خیلی بهتر و مرتبط تری دریافت می کنید. این رویکرد طراحی پرامپت های مؤثر برای دستور دادن به مدل جهت انجام یک وظیفه خاص، همان چیزی است که در این راهنما به آن مهندسی پرامپت گفته میشود.
LLMهای امروزی قادر به انجام انواع وظایف پیشرفته ای هستند که از تولید یا خلاصه سازی متن تا استدلال ریاضی و تولید کد را شامل میشود.
فرمت بندی پرامپت
یک پرامپت استاندارد دارای فرمت زیر است:
<سوال>؟
یا
<دستور>
شما میتوانید این را به یک فرمت پرسش و پاسخ (QA) تبدیل کنید:
Q: <Question>?
A:
این روش که به پرامپت بدون مثال (zero-shot prompting) نیز شناخته میشود، مستقیماً از مدل زبانی میخواهد تا بدون ارائه مثال یا نمونه، به پرسش پاسخ دهد. گرچه برخی مدلهای بزرگ زبان این قابلیت را دارند، اما موفقیت آن به پیچیدگی وظیفه، دانش مورد نیاز و دامنه آموزش مدل بستگی دارد.
در مقابل، پرامپت با مثال (few-shot prompting) روشی شناخته شده و موثر است که در آن با ارائه مثالهای مشخص، مدل را به سمت پاسخ مورد نظر هدایت میکنیم.
فرمت پرامپت بستگی به وظیفه در دست دارد. به عنوان مثال، شما میتوانید یک وظیفه “طبقهبندی” ساده را انجام دهید و مثالهایی را ارائه دهید که وظیفه را به این شکل نشان میدهند:

پرامپتهای با مثال، یادگیری در متن (in-context learning) را امکان پذیر میکنند، که توانایی مدلهای زبان برای یادگیری وظایف است. ما در بخشهای بعدی به طور گستردهتری درباره پرامپت بدون مثال و پرامپت با مثال بحث خواهیم کرد.
عناصر یک پرامپت
همانطور که ما مثالها و کاربردهای بیشتری از مهندسی پرامپت را پوشش میدهیم، متوجه خواهید شد که یک پرامپت از عناصر ثابتی تشکیل شده است.
- دستورالعمل (Instruction): این بخش مشخص میکند که میخواهید مدل چه کاری انجام دهد. مثلاً، میتوانید بگویید “یک شعر کوتاه در مورد عشق بنویس” یا “این متن را به زبان اسپانیایی ترجمه کن”. دستورالعمل هر چه دقیقتر باشد، مدل میتواند پاسخ بهتری تولید کند.
- زمینه (Context): این بخش شامل اطلاعات اضافی است که به مدل کمک میکند تا بهتر موضوع را درک کند. مثلاً اگر میخواهید در مورد یک فیلم خاص پرامپتی بدهید، میتوانید خلاصهای از فیلم یا نام کارگردان آن را نیز ذکر کنید.
- داده ورودی (Input Data): این بخش شامل دادهای است که میخواهید مدل بر اساس آن پردازش انجام دهد. مثلاً، اگر میخواهید یک متن را خلاصه کنید، متن اصلی شما، داده ورودی است.
- نشانگر خروجی (Output Indicator): این بخش مشخص میکند که چه نوع خروجیای انتظار دارید. مثلاً، میتوانید بگویید “یک لیست با سه مورد” یا “یک پاراگراف کوتاه”.
به طور خلاصه، دستورالعمل به مدل میگوید چه کاری انجام دهد، زمینه به مدل کمک میکند تا بهتر موضوع را درک کند، داده ورودی به مدل دادهای میدهد که باید روی آن کار کند و نشانگر خروجی مشخص میکند که چه نوع پاسخی انتظار دارید. با ترکیب مناسب این عناصر، میتوانید پرامپتهای بسیار مؤثری ایجاد کنید که به شما امکان میدهند از قابلیتهای مدلهای زبانی بزرگ به بهترین شکل استفاده کنید.
برای نشان دادن بهتر عناصر پرامپت، در اینجا یک پرامپت ساده که هدف آن انجام یک وظیفه طبقهبندی متن است آورده شده است:
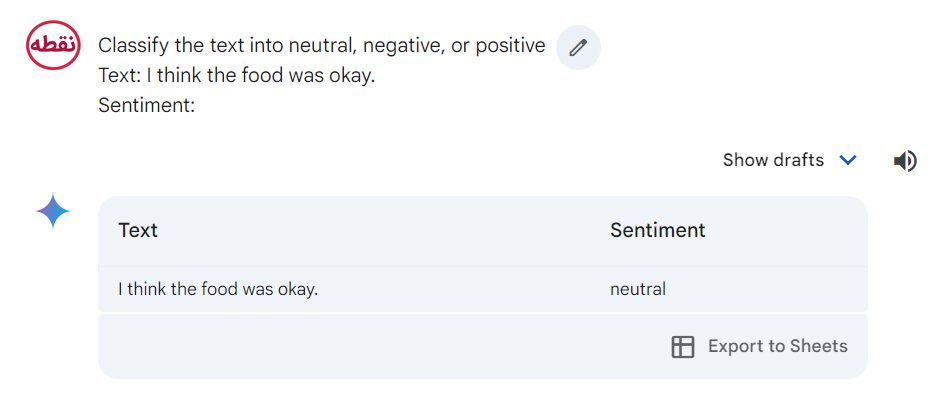
در مثال پرامپت بالا، دستورالعمل مربوط به وظیفه طبقهبندی است، “Classify the text into neutral, negative, or positive”.
داده ورودی مربوط به قسمت “I think the food was okay” است و نشانگر خروجی “Sentiment:” استفاده شده است.
جالب است که هوش مصنوعی Gemini در مثال فوق، اطلاعات بیشتری شامل کد پایتون مربوط به پرامپت را برای ما فراهم نمود.
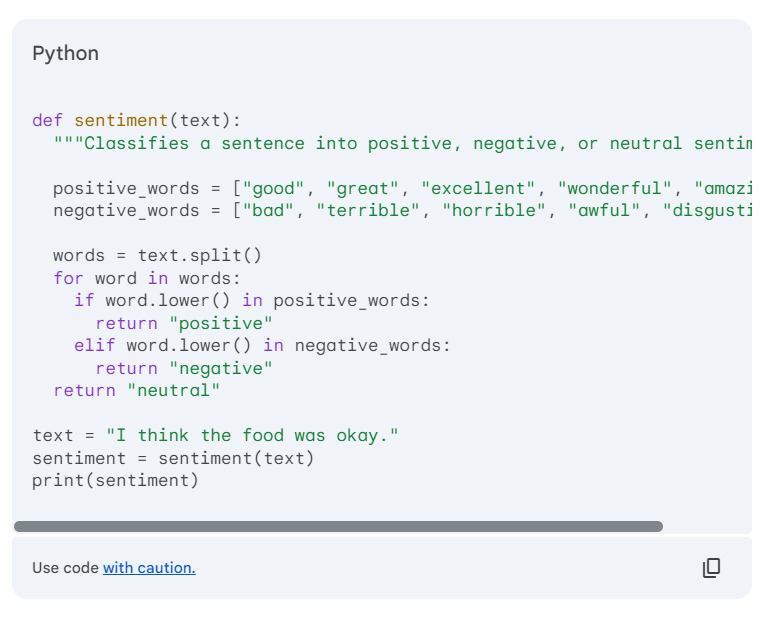
توجه داشته باشید که این مثال ساده از زمینه استفاده نمیکند، اما زمینه نیز میتواند به عنوان بخشی از پرامپت ارائه شود. زمینه برای این پرامپت طبقه بندی متن میتواند مثالهای اضافی باشد که به عنوان بخشی از پرامپت ارائه میشوند تا به مدل کمک کند وظیفه را بهتر درک کند و نوع خروجیهایی را که انتظار دارید هدایت کند.
شما نیازی به همه چهار عنصر برای یک پرامپت ندارید و فرمت دستور بستگی به کاری که می خواهیم انجام شود دارد. در ادامه به بررسی مثالهای ملموس بیشتری خواهیم پرداخت.
نکات کلی برای طراحی پرامپتها
در اینجا چند نکته برای طراحی پرامپتها آورده شده است:
1- شروع ساده
هنگام شروع طراحی پرامپت، باید به یاد داشته باشید که این کار، یک فرایند تکراری است که نیاز به آزمایشهای زیادی برای رسیدن به نتیجه مطلوب دارد. استفاده از یک محیط ساده مانند OpenAI یا Poe یک نقطه شروع خوب است. شما میتوانید با پرامپتهای ساده شروع کنید و به تدریج عناصر و زمینههای بیشتری اضافه کنید تا به نتایج بهتر برسید. تکرار پرامپت و بهبود بخشیدن آن در طول مسیر حیاتی است. همانطور که راهنما را میخوانید، خواهید دید که اغلب سادگی و دقت بیشتر نتایج بهتری به ما میدهد.
بیشتر بخوانید
چت جی پی تی چیست و چه کاربردهایی دارد؟ همه چیز درباره ChatGPT
آشنایی با پلتفرم Poe.com
چت جی پی تی فارسی – ChatGPT Farsi
هنگامی که یک وظیفه بزرگ دارید که شامل چندین زیر وظیفه مختلف است، ابتدا آن کار را به چند کار سادهتر تقسیم کنید و به تدریج، ساختار را بزرگتر و جزئیات را اضافه کنید. این کار از پیچیدگی زیاد فرآیند طراحی پرامپت در ابتدای کار جلوگیری میکند.
2- دستورالعمل (The Instruction)
شما میتوانید با استفاده از افعال در پرامپت خود، به هوش مصنوعی بگویید که چه انتظاری از آن دارید.
افعالی مانند:
Write = … را بنویس
Classify = … را دسته بندی کن
Summarize = … را خلاصه کن
Translate = … را ترجمه کن
Order = … را مرتب کن
برای رسیدن به بهترین نتیجه، آزمایشهای مختلفی لازم است. پرامپت های خود را با کلمات کلیدی، زمینهها و اطلاعات متنوع امتحان کنید تا بهترین گزینه برای کارتان را پیدا کنید. هرچه زمینه و اطلاعات شما به موضوع مورد نظرتان نزدیکتر باشد، نتیجه دقیقتری خواهید گرفت.
برخی توصیه میکنند که دستورات را در ابتدای پرامپت قرار دهید. توصیه برخی دیگر این است که از جداکنندهای مانند “” برای جدا کردن دستور و زمینه استفاده کنید.
به عنوان مثال:
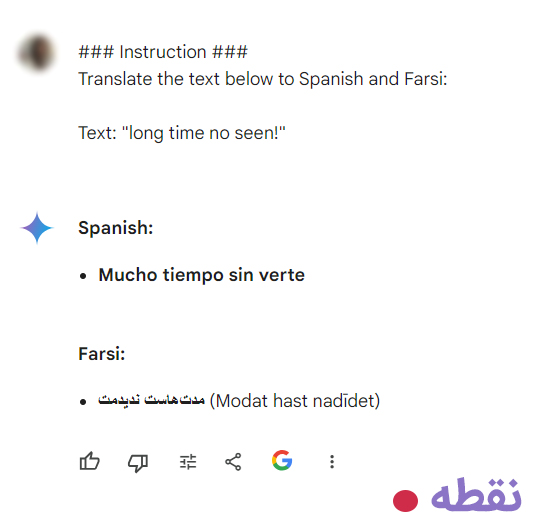
3- اختصاصی بودن پرامپت (Specificity)
درباره دستورالعمل و وظیفهای که میخواهید مدل انجام دهد بسیار خاص باشید. هرچه پرامپت توصیفیتر و جزئیتر باشد، نتایج بهتر خواهد بود. این موضوع خصوصاً زمانی مهم است که یک نتیجه یا سبک تولید خاص را دنبال میکنید.
نمی توان با یک توکن یا یک کلمه کلیدی خاص، به نتایج بهتر رسید. مهم این است که یک فرمت خوب و پرامپت توصیفی داشته باشید.
ارائه مثال در پرامپت برای داشتن خروجی با فرمتهای خاص، بسیار موثر است.
هنگام طراحی پرامپت، باید طول پرامپت را نیز در نظر بگیرید؛ زیرا محدودیتهایی در مورد طول پرامپت وجود دارد. دقت کردن به اینکه چقدر خاص و دقیق باشید نیز مهم است. افزودن جزئیات غیر ضروری لزوماً رویکرد مناسب نیست. جزئیات باید مرتبط باشند و به انجام وظیفه مورد نظر کمک کنند. دانستن ماهیت و میزان جزئیات، چیزی است که نیاز به آزمایش زیادی دارد.
به عنوان مثال، می خواهیم یک پرامپت ساده برای استخراج اطلاعات خاص از یک متن را امتحان کنیم.
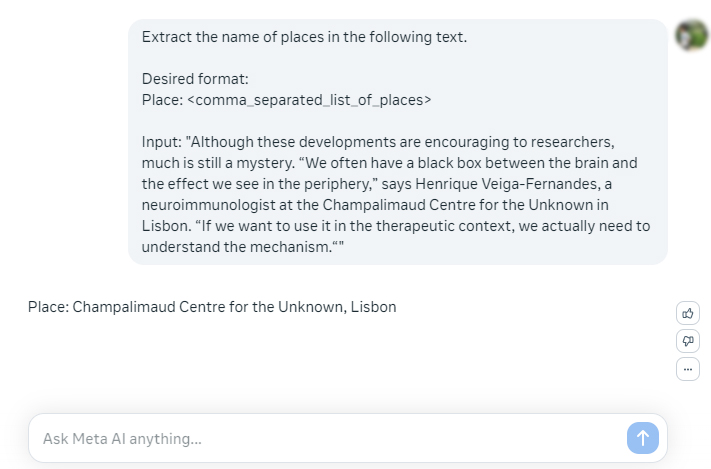
4- از بی دقتی بپرهیزید (Avoid Impreciseness)
وقتی میخواهیم پرامپت های دقیق و روشنی به یک هوش مصنوعی بدهیم، نباید بیش از حد پیچیده و فنی صحبت کنیم. گاهی اوقات، سادگی و مستقیم بودن، بهترین راه برای رساندن منظور است. درست مثل وقتی میخواهیم با کسی صحبت کنیم، هرچه رک تر و خلاصه تر حرف بزنیم، طرف مقابل هم بهتر متوجه منظور ما میشود.
به عنوان مثال، ممکن است علاقهمند به یادگیری مفهوم مهندسی پرامپت باشید. شما ممکن است چیزی شبیه به این را امتحان کنید:
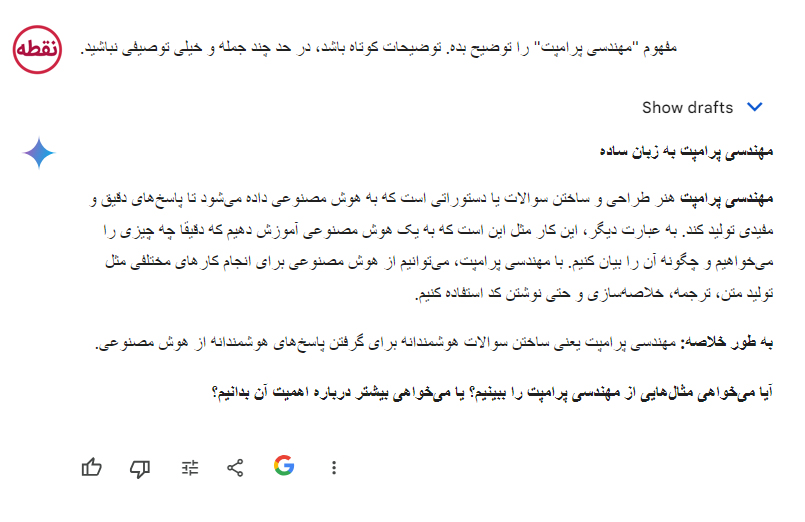
از پرامپت بالا مشخص نیست که چند جمله باید استفاده شود و چه سبکی باشد. شما ممکن است پاسخهای خوبی از پرامپتهای بالا بگیرید، اما پرامپت بهتر، پرامپتی است که بسیار خاص، مختصر و مفید باشد. چیزی شبیه به این:

5- پرامپت مثبت یا منفی؟
یکی دیگر از نکات رایج هنگام طراحی پرامپت، اجتناب از گفتن آنچه نباید انجام شود و تنها گفتن آنچه باید انجام شود، می باشد. این کار باعث تشویق به خاص بودن بیشتر و تمرکز بر جزئیاتی میشود که به دریافت پاسخهای خوب از مدل منجر میشود.
در اینجا مثالی از یک چت بات توصیه فیلم است که دقیقاً به خاطر نحوه نوشتن دستورالعمل منفی – تمرکز بر آنچه نباید انجام دهد – شکست خورده است:
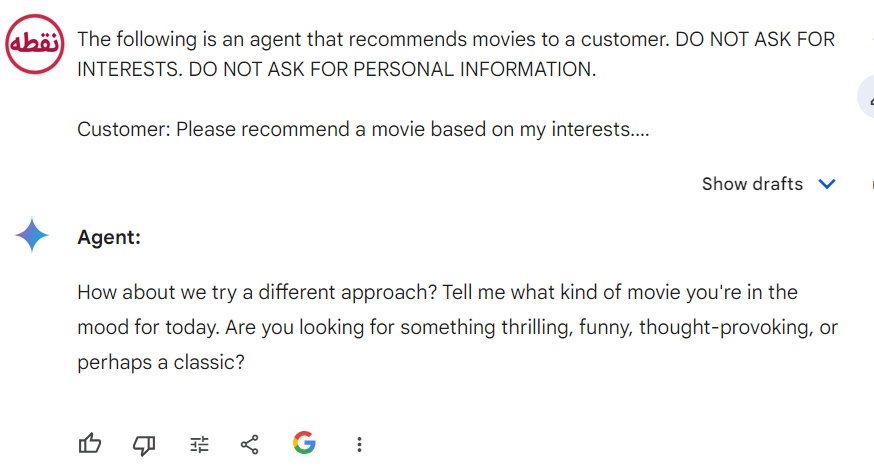
در ادامه یک پرامپت بهتر می نویسم:
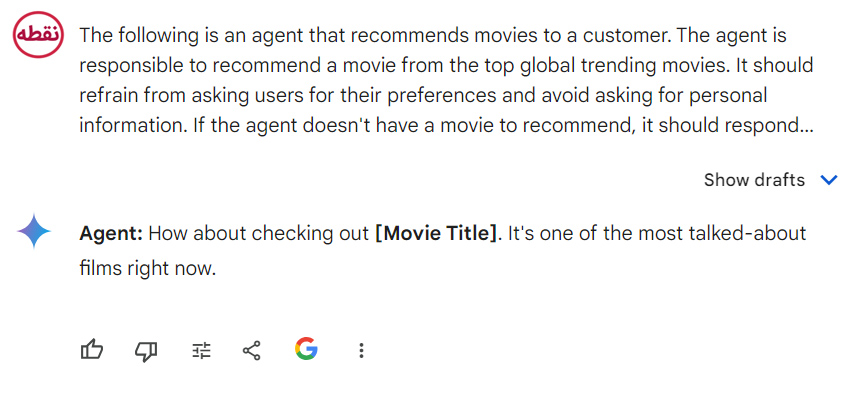
مثالهایی از کاربرد پرامپتها
بخش قبلی یک مثال پایه از نحوه پرامپت نوشتن با مدلهای زبان بزرگ (LLMs) را معرفی کردم. این بخش مثالهای بیشتری از نحوه استفاده از پرامپتها برای انجام وظایف مختلف و معرفی مفاهیم کلیدی ارائه خواهم داد. اغلب، بهترین راه برای یادگیری مفاهیم، از طریق مشاهده مثالها است. چند مثال زیر نشان میدهد که چگونه میتوان با استفاده از پرامپتهای خوب و مناسب، وظایف مختلفی را انجام داد.
خلاصه سازی متن (Text Summarization)
یکی از کاربردهای جذاب هوش مصنوعی در زمینه زبان، توانایی خلاصه سازی متون است. با استفاده از این قابلیت، میتوانیم مقالات طولانی و پیچیده را به خلاصههایی کوتاه و مفید تبدیل کنیم. این قابلیت، به خصوص در دنیای امروز که حجم اطلاعات بسیار زیاد است، خیلی مفید و کاربردی است. برای درک بهتر این موضوع، بیایید یک مثال عملی از خلاصهسازی را بررسی کنیم.
فرض کنید شما علاقهمند به یادگیری درباره آنتیبیوتیکها هستید، میتوانید یک پرامپت شبیه به این را امتحان کنید:

“A:” یک فرمت پرامپت صریح است که شما در پرسش و پاسخ استفاده میکنید. شما از آن در اینجا برای گفتن به مدل استفاده کردید که پاسخی در آینده انتظار میرود. در این مثال، مشخص نیست که این چگونه مفید است یا نه استفاده کردن از آن، اما ما آن را برای مثالهای بعدی میگذاریم. فرض کنیم که این اطلاعات بیش از حد زیاد است و شما میخواهید آن را بیشتر خلاصه کنید. در واقع، میتوانید به مدل دستور دهید تا آن را در یک جمله خلاصه کند، مانند این:

استخراج اطلاعات (Information Extraction)
مدلهای زبانی هوش مصنوعی علاوه بر اینکه برای تولید متنهای طبیعی آموزش دیدهاند، در انجام طیف گستردهای از کارهای مرتبط با پردازش زبان طبیعی مثل طبقه بندی اطلاعات نیز بسیار توانمند هستند. به عنوان نمونه، میتوان از آنها برای استخراج اطلاعات خاص از پاراگرافهای مختلف استفاده کرد. به مثال زیر توجه نمایید:

راههای زیادی برای بهبود نتایج بالا وجود دارد، اما خوب، برای این مرحله همین هم عالی است!
پرسش و پاسخ (Question Answering)
یکی از کلیدهای گرفتن پاسخهای دقیق و هدفمند از یک مدل هوش مصنوعی، طراحی دقیق و ساختارمند پرسشها یا همان پرامپتها است. همانطور که پیشتر اشاره شد، یک پرامپت خوب میتواند ترکیبی از دستورالعملهای واضح، زمینههای مرتبط، ورودیهای مشخص و قالب خروجی دلخواه باشد تا به نتیجه مطلوب تری برسیم. اگرچه وجود همه این اجزا الزامی نیست، اما هر چه دستورالعملها دقیق تر و خاص تر باشند، پاسخ مدل نیز به مراتب بهتر خواهد بود. در ادامه، مثالی عملی از چگونگی ساخت یک پرامپت ساختارمندتر برای شما آورده شده است.

طبقه بندی متون (Text Classification)
تاکنون از دستورالعملهای ساده برای انجام کارها استفاده کردهایم. اما به عنوان یک مهندس پرامت، شما باید در ارائه دستورالعملهای بهتر مهارت پیدا کنید. اما این تمام ماجرا نیست! خواهید دید که برای موارد استفاده دشوارتر، تنها ارائه دستورالعمل کافی نخواهد بود. در اینجا است که باید بیشتر به زمینه و عناصر مختلفی که میتوانید در یک پرامت استفاده کنید، فکر کنید. عناصر دیگری که میتوانید ارائه دهید، دادههای ورودی یا مثالها هستند.
بیایید با ارائه یک مثال از طبقهبندی متن، این موضوع را نشان دهیم.
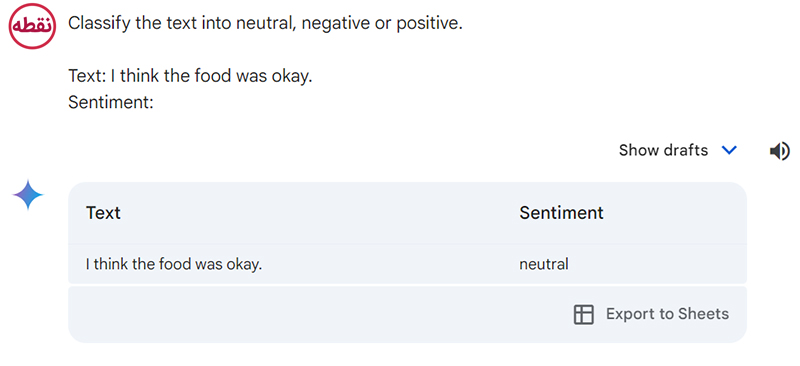
مکالمه
یکی از جذابترین قابلیتهای مهندسی پرامپت، این است که میتوانید به مدلهای زبانی بزرگ (LLM) دقیقاً بگویید چگونه فکر کنند، چه کاری انجام دهند و چه شخصیتی داشته باشند. این ویژگی، بهخصوص در طراحی سیستمهای گفتوگو مانند چتباتهای خدمات مشتری، بسیار کاربردی است.
فرض کنید میخواهیم یک چتبات طراحی کنیم که بتواند به سوالات فنی و علمی، پاسخهای دقیق و تخصصی بدهد. با استفاده از مهندسی پرامپت، میتوانیم به صراحت به مدل بگوییم که باید نقش یک متخصص در زمینه علم و فناوری را ایفا کند. این فرایند را گاهی اوقات “نقشدهی” یا role prompting مینامیم.
به مثال زیر توجه کنید:

دستیار تحقیقاتی هوش مصنوعی ما کمی بیش از حد فنی به نظر میرسد، درست است؟ خوب، بیایید این رفتار را تغییر دهیم و به گونهای دستور دهیم که پاسخهای ساده تری بدهد.

پیشرفت خوبی بود! میتوانید به بهبود پرامپت ادامه دهید. اگر مثالهای بیشتری اضافه کنید، ممکن است نتایج بهتری بدست آورید.
تولید کد
یکی از کاربردهای بسیار جذاب هوش مصنوعیهای زبانی بزرگ (LLM) کمک به برنامهنویسی است. Copilot یکی از مثالهای موفق در این زمینه است. با دادن پرامپت مناسب به این ابزارها، میتوانیم طیف وسیعی از کدها را تولید کنیم. برای اینکه بهتر متوجه این موضوع شویم، چند مثال عملی را بررسی میکنیم.
ابتدا، بیایید یک برنامه ساده که به کاربر خوشامد میگوید را امتحان کنیم.
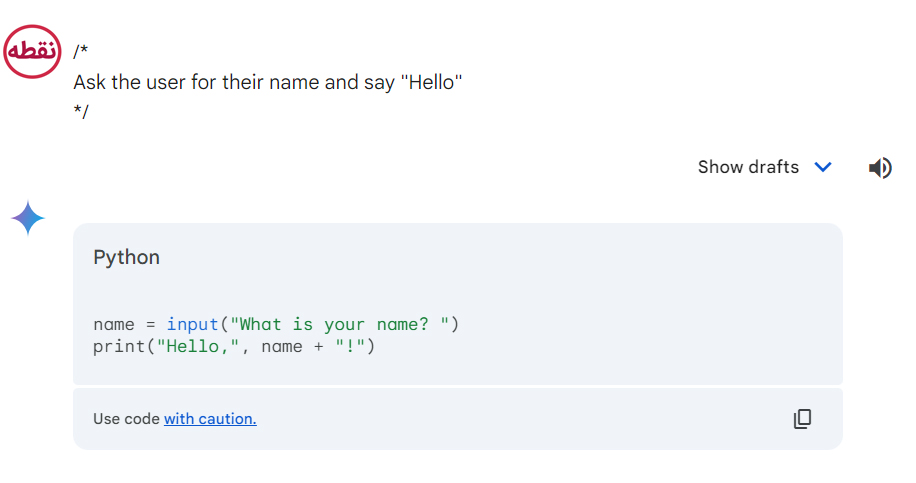
توجه کنید که حتی نیاز نبود زبان را مشخص کنید.
بیایید سطح کار را تغییر دهیم. مثال زیر نشان میدهد که چگونه LLMها میتوانند با کمی تلاش بیشتر در طراحی پرامپتها، قدرتمند باشند.
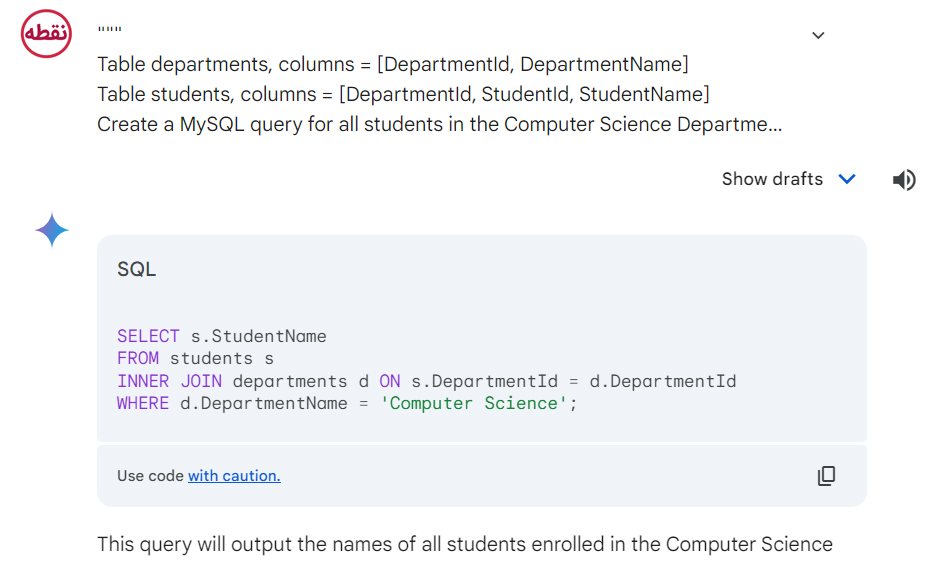
با تمرین بیشتر، میتوانید مهارت تان در کدنویسی با هوش مصنوعی را ارتقا داده و سرعت توسعه نرمافزارهای خود را به طور چشمگیری افزایش دهید.
استدلال
احتمالاً یکی از چالشبرانگیزترین کارهایی که امروزه از یک مدل زبانی بزرگ (LLM) انتظار میرود، انجام وظایفی است که نیازمند نوعی استدلال منطقی هستند. استدلال، به دلیل طیف گستردهای از کاربردهای پیچیدهای که میتواند برای LLMها ایجاد کند، یکی از جالبترین حوزههای پژوهش محسوب میشود.
پیشرفتهایی در زمینه بهبود توانایی LLMها در انجام محاسبات ریاضی صورت گرفته است. با این حال، باید توجه داشت که مدلهای زبانی فعلی هنوز در انجام استدلالهای پیچیده با مشکل مواجه هستند و این امر نیازمند استفاده از روشهای مهندسی پرامپت (prompt engineering) پیشرفتهتری است. در ادامه به بررسی دقیق این روشهای پیشرفته خواهیم پرداخت. در این بخش، برای آشنایی اولیه شما با قابلیتهای محاسباتی LLMها، چند مثال ساده ارائه خواهیم کرد.

هوش مصنوعی به درستی به مسئله پاسخ داد.
حال مثالی دیگر با پیچیدگی بیشتر را بررسی می کنیم:

هوش مصنوعی gemini به زیبایی این معما را برایمان حل کرد!



