
مدل زبان بزرگ (LLM) نوعی برنامه هوش مصنوعی است که قابلیت شناسایی و تولید متن را دارد و میتواند کارهای دیگری نیز انجام دهد. این مدلها با استفاده از مجموعههای دادههای عظیم و یک نوع شبکه عصبی به نام مدل تبدیلگر آموزش دیدهاند که به آنها امکان میدهد تا نحوه کارکرد حروف، کلمات و جملات را درک کنند.
LLM ها بر پایه یادگیری ماشینی ساخته شده و از یادگیری عمیق برای درک زبان طبیعی استفاده میکنند. امکان سفارشیسازی یا تنظیم این مدلها برای انجام وظایف خاص مانند تفسیر پرسشها و تولید پاسخها و یا ترجمه متون از یک زبان به زبان دیگر وجود دارد.
این مدلها در کاربردهای مختلفی از جمله تولید متن، تولید کد، بازیابی و خلاصهسازی محتوا، هوش مصنوعی مکالمهای و موارد دیگر به کار میروند. آینده LLM ها بسیار امیدوارکننده است و انتظار میرود که با پیشرفتهایی در زمینههای آموزش تصویری و صوتی، تحولات در محیط کار و پیشرفت هوش مصنوعی محاورهای روبرو شویم.
با توجه به تعداد زیاد مدلهای موجود، یافتن یک مدل زبان بزرگ که به خوبی پاسخگوی نیازهای خاص شما باشد، ممکن است کاری دشوار باشد. این حوزه به سرعت در حال تحول است و هر هفته مدلهای جدید و نسخههای بهینهسازی شدهای معرفی میشوند. بنابراین، هر فهرستی از LLM ها و نحوه استفاده از آنها به سرعت منسوخ میشود. به همین دلیل است که توضیح دادن در مورد هر یک از LLM های برتر و تعیین نقاط قوت و ضعف آنها منطقی نیست؛ به جای آن، در این مقاله، ما سعی میکنیم معیارهایی را به اشتراک بگذاریم که میتوانید برای تجزیه و تحلیل مدلها استفاده کنید و بررسی کنید که آیا آنها به نیازها و محدودیتهای شما پاسخ میدهند یا خیر.
این مقاله میتواند به عنوان راهنمای مقدماتی برای ارزیابی یک مدل تازه انتشار یافته بر اساس تعدادی از ویژگیهای اصلی استفاده شود، که بر این اساس، ما نیز نحوه مقایسه مدلها را به شما نشان خواهیم داد.
بیشتر بخوانید:
پردازش زبان طبیعی چیست؟ همه چیز درباره NLP
یادگیری ماشین چیست و چگونه کار می کند؟
شبکه عصبی چیست؟
تشخیص گفتار
ویژگیهای کلیدی یک LLM
ویژگیهای کلیدی یک LLM که باید در نظر بگیرید، عبارتند از:
- اندازه
- نوع معماری
- عملکرد benchmark
- فرآیندهای آموزش و سوگیریها
- مجوز/دسترسی
اندازه یک LLM چقدر است؟
هنگام انتخاب یک LLM، مهمترین محدودیت شما بودجهتان است. اجرای LLM ها میتواند بسیار گران باشد، بنابراین لازم است مدلی را انتخاب کنید که با بودجه شما هماهنگ است. در این راستا، تعداد پارامترهای یک LLM میتواند نشاندهنده هزینه آن باشد.
تعداد پارامترهای یک مدل چیست؟
تعداد پارامترها، تعداد وزنها (weights) و بایاسهایی(biases) را که مدل در طول آموزش تنظیم میکند و برای محاسبه خروجی خود از آنها استفاده میکند، مشخص میکند. چرا تعداد پارامترها در یک مدل مهم است؟ تعداد پارامترها تخمینی تقریبی از هزینه عملکرد و سرعت استنتاج مدل را میدهد. این دو معمولاً نسبت مستقیم با یکدیگر دارند. این به این معناست که هرچه تعداد پارامترهای یک مدل بیشتر باشد، هزینه تولید خروجی توسط آن بالاتر خواهد بود.
سرعت استنتاج یک مدل چیست؟
سرعت استنتاج یک مدل زبانی، زمانی را نشان میدهد که مدل برای پردازش یک ورودی صرف میکند. به عبارت ساده، این معیار سرعت خروجی مدل است. باید توجه داشت که سرعت استنباط و عملکرد یک مدل، موضوعی چندوجهی و پیچیده است که نمیتوان تنها با تعداد پارامترها سنجیده شود. با این حال، برای اهداف این مقاله، این موضوع، تخمینی از عملکرد بالقوه مدل را ارائه میدهد. خوشبختانه روشهای ثابت شدهای برای کاهش زمان استنباط مدلهای یادگیری ماشین وجود دارد.
| مدل یا سری مدل | تعداد پارامترها |
|---|---|
| میسترال | 7.24B, 46.7B |
| GPT-4 | 1.76T (تخمینی) |
| GPT-3 | 124M، 350M، 760M، 1.3B، 2.7B، 6.7B، 13B، 175B |
| LLaMA 2 | 6.74B، 70B |
| BART | 139M، 406M |
| BERT | 110M، 336M |
| فالکن | 7B، 40B |
مدلهای متوسط معمولاً کمتر از ۱۰ میلیارد پارامتر دارند و مدلهای بسیار ارزان قیمت دارای زیر ۱ میلیارد پارامتر هستند. با این حال، مدلهایی که زیر ۱ میلیارد پارامتر دارند معمولاً قدیمی هستند یا برای کاربرد تولید متن طراحی نشدهاند. مدلهای گرانقیمت بیش از ۱۰۰ میلیارد پارامتر دارند، مانند GPT-4 که ادعا میکند دارای ۱.۷۶ تریلیون پارامتر است. اکثر سریهای مدل مانند LLaMa 2، Mistral، Falcon و GPT دارای نسخههای کوچکی هستند که کمتر از ۱۰ میلیارد پارامتر دارند و نسخههای بزرگتری که بین ۱۰ تا ۱۰۰ میلیارد پارامتر دارند.
انواع مختلف LLMها چیست؟
به طور کلی، تمام LLM های مبتنی بر معماری ترانسفورمر را میتوان به سه دسته تقسیم کرد:
- فقط-رمزگذار (encoder-only)
- رمزگذار-رمزگشا (encoder-decoder)
- فقط-رمزگشا (decoder-only)
دستهبندی که مدل زبان بزرگ به آن تعلق دارد، به تعیین کاربرد طراحی شده آن و عملکرد تولید متن آن کمک میکند.
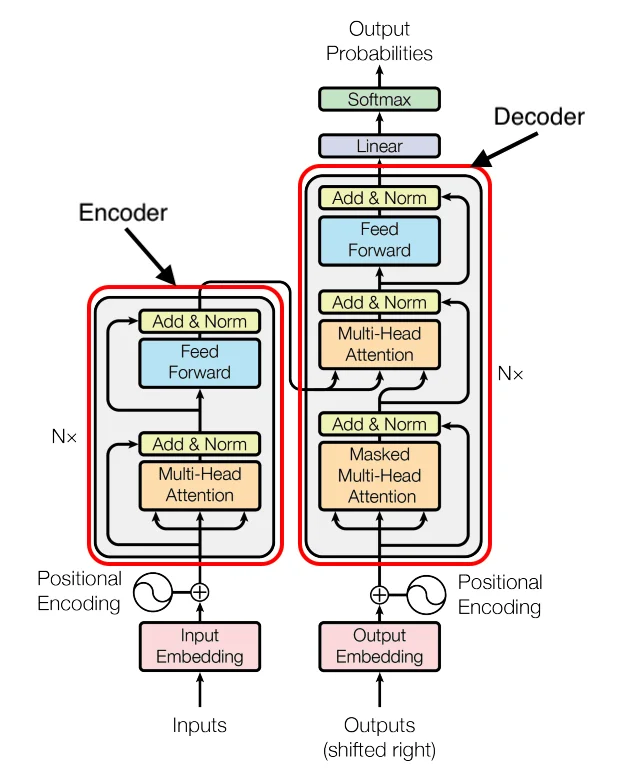
مدل فقط-رمزگذار چیست؟
مدلهای encoder-only فقط از یک رمزگذار استفاده میکنند که متن ورودی را رمزگذاری و طبقهبندی میکند. این نوع مدلها برای قرار دادن متن در یک دستهبندی مشخص مفید هستند. BERT، شاخصترین مدل encoder-only، به عنوان یک مدل زبان با ماسک (MLM) و برای پیشبینی جمله بعدی (NSP) آموزش دیده است. هر دوی این کاربردها، نیازمند شناسایی عناصر اصلی در یک جمله هستند.
مدل رمزگذار-رمزگشا چیست؟
مدلهای encoder-decoder ابتدا متن ورودی را رمزگذاری میکنند (همانند مدلهای فقط رمزگذار) و سپس بر اساس ورودیهایی که حالا رمزگذاری شدهاند، پاسخی تولید یا رمزگشایی میکنند. BART نمونهای از معماری مدل encoder-decoder است. از این نوع مدلها هم برای تولید متن و هم برای درک متن استفاده میشود، به همین دلیل برای ترجمه مفید هستند. BART میتواند برای خلاصهسازی مقالات و متون طولانی به خروجیهای قابل فهم مورد استفاده قرار گیرد.
BART-Large-CNN، نسخهای بهینهسازی شده از BART است که برای تولید خلاصه متن پس از بهینهسازی روی مجموعهای از مقالات خبری آموزش دیده است. به طور کلی، مدلهای encoder-decoder میتوانند هم برای موارد استفاده از درک متن و هم برای تولید متن به کار روند.
مدل فقط-رمزگشا چیست؟
مدلهای decoder-only برای رمزگشایی یا تولید کلمه یا نشانه بعدی بر اساس یک سرنخ داده شده استفاده میشوند. این مدلها تنها برای تولید متن به کار گرفته میشوند. از نظر کارایی تولید زبان، مدلهای فقط-رمزگشا برای تولید متن خالص مفیدتر هستند، زیرا آموزش آنها سادهتر است. سری مدلهایی مانند GPT، Mistral و LLaMa همگی decoder-only هستند. اگر کاربرد شما عمدتاً نیازمند تولید متن است، مدلهای فقط-رمزگشا راه حل مناسبی هستند.
توجه: Mistral’s 8x7B (که به Mixtral نیز شناخته شده است) از معماری منحصر به فردی به نام mixtral of experts استفاده میکند. تصور میشود که GPT-4 ممکن است محصولی از تکنیک مشابه باشد. بنابراین، آنها به راحتی در دستهبندی فقط-رمزگشا قرار نمیگیرند. علاوه بر این، تکنیکهای معماری جدیدی وجود دارند که در هیچ یک از این دستهها قرار نمیگیرند، مانند تولید تقویتشده با بازیابی (RAG).
| سری مدلها | نوع |
| Mistral | Decoder-only |
| GPT | Decoder-only |
| LLaMa | Decoder-only |
| BART | Encoder-decoder |
| BERT | Encoder-only |
| Falcon | Decoder-only |
چگونه کیفیت عملکرد یک LLM را اندازه گیری کنیم
برای سنجش کیفیت یک مدل زبانی بزرگ (LLM)، چندین روش اندازهگیری وجود دارد که هدف آنها ارزیابی توانایی مدل در درک، تفسیر و پاسخگویی دقیق به پرامپتهای مختلف است. روشهای سنجش عملکرد مدلهای زبانی بر اساس کاربردهای مورد نظر آنها متفاوت است. برای نمونه، BERT که یک مدل زبانی تنها با قابلیت رمزگذاری است، برای تولید متن طراحی نشده است، بنابراین کیفیت آن به شیوهای متفاوت از GPT-3، که یک مدل با قابلیت رمزگشایی است، سنجیده میشود. در اینجا، برخی از روشهای به کار رفته برای ارزیابی کیفیت تولید متن توسط LLMها توضیح داده شده است.

یکی از روشهای متداول برای سنجش کیفیت یک مدل زبان تولیدی، دادن آزمون به آن است. به عنوان مثال، عملکرد GPT-4 با استفاده از مجموعهای از آزمونهای آکادمیک با عملکرد GPT-3.5 مقایسه شد. در واقع، مدل تحت ارزیابی برخی از آزمونها قرار میگیرد و سپس نتایج آن با نمرات انسانها و مدلهای قبلی مقایسه میشود. این روش، راهکار مؤثری برای ارزیابی تواناییهای استدلال مدل در محیط آکادمیک است. در اینجا فهرست کوتاهی از برخی از آزمونهایی که GPT-4 در آنها شرکت کرده و نتایج آن با GPT-3.5 و میانگین انسانها مقایسه شده، آورده شده است:
| امتحان | امتیاز GPT 4 | امتیاز GPT 3.5 | امتیاز میانگین انسانها |
| LSAT | 163 | 149 | 152 |
| SAT | 1,410 | 1,260 | 1028 |
| AP US History | 5 | 4 | 2.52 |
معیاری مشابه برای ارزیابی عملکرد در آزمونهای آکادمیک، استفاده از مجموعههای داده مختلف پرسش و پاسخ (QnA) برای مدلها است. این روشی است که در Hugging Face Open LLM Leaderboard استفاده میشود: فهرست مفیدی که LLMهای مختلف را بر اساس دادههای QnA مقایسه میکند. این فهرست امکان ارزیابی ساده LLM را با توجه به هوش عمومی و تواناییهای منطقی آن فراهم میآورد.
چالش استدلال AI2 (ARC)
مجموعه داده ARC شامل “۷۷۸۷ سوال علوم طبیعی” است که به عنوان سوالاتی با “سطوح مختلف دشواری” توصیف شدهاند و “قابل سنجش، انگیزهبخش و جاهطلبانه” هستند. در حقیقت، این سوالات از محافل آکادمیک گرفته شدهاند و سطوح کلاس سوم تا نهم را در بر میگیرند. در اینجا سه نمونه از مقاله تحقیقاتی آن آورده شده است.
- کدام ویژگی یک کانی تنها با نگاه کردن به آن قابل تشخیص است؟ (الف) جلای ظاهری (ب) جرم (ج) وزن (د) سختی
- کدام عنصر بیشترین سهم را در هوایی که تنفس میکنیم دارد؟ (الف) کربن (ب) نیتروژن (ج) اکسیژن (د) آرگون
- اولین مرحله از فرآیند تشکیل سنگهای رسوبی چیست؟ (الف) فرسایش (ب) رسوب (ج) فشردگی (د) سیمانی شدن
درک زبان چندکاره بزرگ (MMLU)
Massive Multitask Language Understanding مجموعهای از آزمونهای چندگزینهای شامل ۱۵٬۹۰۸ سوال از «شاخههای مختلف دانش» است که موضوعاتی از علوم انسانی، علوم اجتماعی، علوم سخت و سایر زمینههایی که برخی افراد به یادگیری آن علاقهمند هستند را در بر میگیرد. این مجموعه دارای سطوح مختلف دشواری، از «ابتدایی»، «دبیرستان»، «کالج» و «حرفهای» است و بنابراین، دامنهی سوالات ARC را پشت سر میگذارد. این مجموعه بیشتر برای آزمایش دانش واقعی مدلها استفاده میشود.
سه معیار ARC، MMLU و WinoGrande برای اندازهگیری وضعیت عمومی هوش، دانش واقعی و توانایی استدلال یک مدل مفید هستند. این معیارها هنگام انتخاب یا تنظیم دقیق یک LLM مهم میباشند. به طور کلی، شما باید LLMای را انتخاب کنید که کمترین حجم یا هزینه (از نظر تعداد پارامترها) و بالاترین امتیازهای معیاری (ARC، MMLU، WinoGrande و غیره) را داشته باشد.
پرامپت نویسی با LLM ها
پیش از نمایش نتایج عملکرد، نیاز است تا روشهای مختلف پرامپت نویسی توسط LLM ها را توضیح دهیم. به طور کلی، سه نوع پرامپت نویسی مختلف هنگام انجام معیارهای QnA وجود دارد: zero-shot، few-shot و one-shot.
Few-shot یا k-shot
پرامپت های Few-shot یا k-shot روشی در یادگیری ماشین هستند که به مدلهای زبانی اجازه میدهند با استفاده از تعداد محدودی مثال (معمولا کمتر از پنج) وظایف جدید را یاد بگیرند. به جای آموزش مدل روی یک مجموعه داده عظیم، با ارائه چند مثال مرتبط، مدل میتواند الگوها را شناسایی کرده و وظیفه مورد نظر را انجام دهد. این روش به ویژه برای مدلهایی که به صورت مداوم در حال یادگیری هستند و باید به سرعت با وظایف جدید تطبیق پیدا کنند، بسیار مفید است. به عبارت دیگر، این روش باعث میشود مدلهای زبانی انعطافپذیرتر و قادر به یادگیری سریعتر شوند.
One-shot
در پرامپت نویسی One-shot، مدل هوش مصنوعی تنها با یک مثال آموزشی (یک شات) آموزش میبیند تا یک وظیفه خاص را انجام دهد. به عبارت دیگر، مدل با دیدن تنها یک نمونه از ورودی و خروجی مورد نظر، قادر میشود تا الگوهای موجود در دادهها را تشخیص داده و برای دادههای جدید پیشبینی انجام دهد. این روش در مواردی که دادههای آموزشی محدود هستند یا هزینه برچسبگذاری دادهها بالاست، بسیار مفید است. پرامپت نویسی One-shot به دلیل سادگی و کارایی، در زمینههای مختلفی مانند پردازش زبان طبیعی، بینایی ماشین و یادگیری تقویتی مورد استفاده قرار میگیرد.
Zero-shot
پرامپت نویسی Zero-shot به توانایی یک مدل زبانی برای تولید پاسخهای معنادار به پرسشهایی که قبلاً در طی آموزش به آن ارائه نشده است، اشاره دارد. به عبارت دیگر، مدل بدون نیاز به مثالهای آموزشی خاص، میتواند به سوالات جدید و ناشناخته پاسخ دهد. این قابلیت به دلیل توانایی مدل در درک ساختار زبان، تشخیص الگوها و استنتاج اطلاعات جدید از اطلاعات موجود است. در پرامپت نویسی Zero-shot، مدل تلاش میکند تا با استفاده از دانش عمومی و درک عمیق خود از زبان، به بهترین شکل ممکن به پرسش کاربر پاسخ دهد. این روش در بسیاری از کاربردهای پردازش زبان طبیعی مانند تولید متن، ترجمه ماشینی و پاسخگویی به سوالات بسیار مفید است.
پرامپت نویسی Zero-shot به دلیل نبود زمینهای مشخص، برای مدل دشوارتر از پرسشگری One-shot یا Few-shot است.
بیشتر بخوانید:
۷ نکته برای نوشتن دستورات پرامپت ChatGPT
۱۵۰ پرامپت ChatGPT برای کارهای مختلف؛ همراه با مثالهای فارسی
جدول مقایسه کیفیت بین مدلهای زبان بزرگ (LLMs)
به خاطر داشته باشید که مقایسه امتیاز Zero-shot با 25-shot فایدهای ندارد. به طور کلی، شما باید نوع پرسشگری را برای مقایسههای کیفی یکسان نگه دارید. علاوه بر این، مقایسه دو داده با همان روش پرسشگری ممکن است به دلیل تفاوتهای روشهای آزمایش، هنوز دقیق نباشد. با این حال، موارد زیر باید مقایسه تقریبی از کیفیت را ارائه دهد:
جدول مقایسهای کیفیت بین مدلهای زبان بزرگ (LLMs) در آزمونهای ARC، MMLU، و WinoGrande با استفاده از روشهای few-shot و zero-shot.
| مدل | ARC-challenging score in % correct | MMLU score (5-shot) in % correct | WinoGrande score in % correct |
| Mistral 7B | 60.0 (25-shot), 55.5 (0-shot) | 60.1 | 78.4 (5-shot), 75.3 (0-shot) |
| LLaMa 2 7B | 43.2 (0-shot) | 44.4 | 69.5 (0-shot) |
| LLaMa 2 13B | 48.8 (0-shot) | 55.6 | 72.9 (0-shot) |
| GPT-4 | 96.3 (25-shot) | 86.4 | 87.5 (5-shot) |
| GPT-3 6.7B | 41.4 (0-shot) | 24.9 | 64.5 (0-shot) |
| Falcon 7B | 47.9 (25-shot) | 27.8 | 72.4 (5-shot) |
| GPT-2 1.5B | 30.3 (25-shot) | 26.5 | 58.3 (5-shot) |
| Mistral 8x7B | 66.0 (25-shot), 59.7 (0-shot) | 71.8 | 81.9 (5-shot), 77.2 (0-shot) |
بهترین مدل زبان بزرگ (LLM) فعلی برای استفاده به عنوان چتبات کدام است؟
با توجه به توضیحاتی که قبلاً اشاره کردم، بررسی این جدول نشان میدهد که از نظر کیفیت کلی، GPT-4 به وضوح بهترین LLM است. با این حال، برای صرفه جویی در هزینه میتوانید مدلهای Mistral را انتخاب کنید. نسخه 8x7B Mistral با استفاده از یک تکنیک منحصر به فرد که چندین مدل Mistral 7b را ترکیب میکند، نتایج با کیفیت بالاتری تولید میکند و مدلی بسیار کارآمد است که در معیارها نیز عملکرد خوبی دارد.
بیشتر بخوانید:
چت جی پی تی چیست و چه کاربردهایی دارد؟ همه چیز درباره ChatGPT
تأثیر دادههای آموزشی بر LLM ها
دیتاستهای آموزشی مختلفی که برای آموزش یا تنظیم مجدد یک مدل خاص استفاده میشوند، ملاحظات مهمی را مطرح میکنند. چه نوع دادهای استفاده شده است؟ آیا دیتاست تنها برای برخی کاربردها مفید است؟ آیا مدل دارای جهتگیریهای زیربنایی است که میتواند بر مدل تأثیر بگذارد؟
چگونگی بروز سوگیری در مدلها، با گرفتن BERT به عنوان مثال برای اکثر مدلهای زبان بزرگ (LLMs)، دادههای آموزشی به طور کلی بسیار گسترده است و برای دادن درک اولیه از زبان به مدل استفاده میشود. BERT با استفاده از ویکیپدیا (۲۵۰۰ میلیون کلمه) و BookCorpus (۸۰۰ میلیون کلمه) پیشآموزی شده است. در بسیاری موارد، مانند مدلهای Mistral، مجموعه دادههای آموزشی تا به امروز به صورت عمومی در دسترس نیست. تحلیل این مجموعههای داده روش خوبی است تا احتمالاً سوگیریهای درونی مدل را پیشبینی کنیم. بیایید به BERT نگاهی بیندازیم که به شدت به مجموعه دادههای ویکیپدیا انگلیسی در آموزش خود تکیه دارد. ویکیپدیا اغلب به عنوان منبعی بیطرف و بدون سوگیری از اطلاعات مطرح میشود. به عنوان مثال، بر اساس مقالهای از گاردین، تنها ۱۶٪ از ویراستاران ویکیپدیا زن هستند و تنها ۱۷٪ از مقالات افراد مشهور به زنان اختصاص دارد. علاوه بر این، تنها ۱۶٪ از محتوای نوشته شده برای آفریقای جنوب صحرا توسط افرادی از همان منطقه نوشته شده است. از BERT، که با استفاده از ویکیپدیا انگلیسی آموزش دیده است، میتوان انتظار داشت که سوگیریهای احتمالی موجود در ویکیپدیا را به ارث برده باشد. شواهدی وجود دارد که نشان میدهد این ممکن است درست باشد. نشان داده شده است که BERT دارای سوگیریهای جنسیتی و نژادی در نتایج خود است. پس، به طور خلاصه، سوگیریها در مجموعههای داده آموزشی برای مدلهای آموزش دیده ممکن است بر تولید متن آنها تأثیر بگذارد. در نظر گرفتن چنین سوگیریهایی مهم است، زیرا بر کاربر نهایی نیز تأثیر میگذارد.
پرسشهای متداول
مدل زبان بزرگ (LLM) چیست؟
مدل زبان بزرگ (LLM) نوعی از هوش مصنوعی است که از تکنیکهای یادگیری عمیق برای درک و تولید متنی شبیه به زبان انسان استفاده میکند. این مدلها با استفاده از حجم وسیعی از دادههای متنی آموزش دیده و میتوانند در انجام دادن وظایف مختلف زبانی نظیر ترجمه، خلاصهسازی، پاسخگویی به سوالات، و نوشتن خلاق کاربرد داشته باشند.
مدلهای زبان بزرگ چگونه کار میکنند؟
LLMs با تجزیه و تحلیل الگوها و ساختارهای موجود در دادههای آموزشیشان کار میکنند. آنها از تکنیکی به نام “معماری ترانسفورمر” استفاده میکنند که به آنها امکان میدهد وزن اهمیت کلمات مختلف در یک جمله یا پاراگراف را سنجیده و پاسخهای منسجم و متناسب با زمینه را تولید کنند.
نمونههایی از مدلهای زبان بزرگ چه هستند؟
برخی از LLMهای شناختهشده عبارتند از سری GPT (Generative Pre-trained Transformer) از OpenAI، BERT (Bidirectional Encoder Representations from Transformers) از Google، و Turing-NLG از Microsoft. هر کدام از اینها ویژگیها و کاربردهای منحصر به فرد خود را دارند.
آیا مدلهای زبان بزرگ قابل اعتماد هستند؟
هرچند LLMها قدرتمند هستند، اما بینقص نیستند. آنها ممکن است اطلاعات نادرست یا دارای تعصب تولید کنند، اگر دادههایی که بر اساس آنها آموزش دیدهاند، حاوی چنین نادرستیها یا تعصباتی باشند. مهم است که کاربران خروجی LLMها را به دقت ارزیابی کنند.
آیا مدلهای زبان بزرگ میتوانند چندین زبان را درک کنند؟
بسیاری از LLMها چندزبانه هستند و میتوانند متنها را در چندین زبان درک و تولید کنند. با این حال، عملکرد در هر زبان ممکن است بر اساس کیفیت و کمیت دادههای آموجود در آن زبان متفاوت باشد.
نگرانیهای اخلاقی در مورد مدلهای زبان بزرگ چه هستند؟
نگرانیهای اصلی شامل مسائل حریم خصوصی میشود، زیرا دادههای آموزشی ممکن است حاوی اطلاعات حساس باشند؛ ترویج تعصبات، زیرا مدلها میتوانند تعصبات موجود در دادهها را تشدید کنند؛ و تأثیر بر اشتغال، زیرا اتوماسیون ممکن است جایگزین مشاغلی شود که شامل وظایف نوشتاری روزمره هستند.
چگونه میتوان از یک مدل زبان بزرگ استفاده کرد؟
میتوان از LLMها از طریق APIهایی که توسط شرکتهایی مانند OpenAI، Google و Microsoft ارائه میشود، دسترسی پیدا کرد. آنها را میتوان در برنامههایی برای اهداف مختلف نظیر چتباتها، دستیاران نویسنده، اتوماسیون خدمات مشتری و موارد دیگر یکپارچه سازی کرد.
آینده مدلهای زبان بزرگ چگونه خواهد بود؟
آینده احتمالاً شامل مدلهایی دقیقتر خواهد بود که بهتر میتوانند متوجه زمینه و ظرافتها شوند، کمتر دارای تعصب بوده و از نظر انرژی کارآمدتر باشند. علاوه بر این، ممکن است شاهد مقررات بیشتری در مورد استفاده از آنها باشیم، به ویژه در زمینههای حریم خصوصی و مسائل اخلاقی.



